|
|
|
Textbook on Computer Arithmetic
Behrooz Parhami: 2007/06/19 || E-mail: parhami@ece.ucsb.edu || Problems: webadmin@ece.ucsb.edu Other contact info at: Bottom of this page || Go up to: B. Parhami's teaching and textbooks or his home page
On June 19, 2007, Professor Parhami's UCSB ECE website moved to a new location. For an up-to-date version of this page, visit it at the new address: http://www.ece.ucsb.edu/~parhami/text_comp_arit.htm
**** The 2nd edition of this book is being prepared for publication in 2007 **** Parhami, Behrooz, Computer Arithmetic: Algorithms and Hardware Designs, Oxford University Press, New York, 2000 (ISBN 0-19-512583-5, 490 + xx pp.). Available for purchase from Oxford University Press and various college or on-line bookstores. Instructor’s manual originally prepared in two volumes: a solutions manual and set of transparency masters (the latter volume now superseded by downloadable PowerPoint presentation files).
Return to:
Top of this page Preface The context of computer arithmetic Advances in computer architecture over the past two decades have allowed the performance of digital computer hardware to continue its exponential growth, despite increasing technological difficulty in speed improvement at the circuit level. This phenomenal rate of growth, which is expected to continue in the near future, would not have been possible without theoretical insights, experimental research, and tool-building efforts that have helped transform computer architecture from an art into one of the most quantitative branches of computer science and engineering. Better understanding of the various forms of concurrency and the development of a reasonably efficient and user-friendly programming model have been key enablers of this success story. The down side of exponentially rising processor performance is an unprecedented increase in hardware and software complexity. The trend toward greater complexity is not only at odds with testability and certifiability but also hampers adaptability, performance tuning, and evaluation of the various tradeoffs, all of which contribute to soaring development costs. A key challenge facing current and future computer designers is to reverse this trend by removing layer after layer of complexity, opting instead for clean, robust, and easily certifiable designs; to devise novel methods for gaining performance and ease-of-use benefits from simpler circuits that can be readily adapted to application requirements. In the computer designers’ quest for user-friendliness, compactness, simplicity, high performance, low cost, and low power, computer arithmetic plays a key role. It is one of oldest subfields of computer architecture. The bulk of hardware in early digital computers resided in accumulator and other arithmetic/logic circuits. Thus, first-generation computer designers were motivated to simplify/share hardware to the extent possible and to carry out detailed cost-performance analyses before proposing a design. Many of the ingenious design methods that we use today have their roots in the bulky, power-hungry machines of 30-50 years ago. In fact computer arithmetic has been so successful that it has, at times, become transparent. Arithmetic circuits are no longer dominant in terms of complexity; registers, memory and memory management, instruction issue logic, and pipeline control have become the dominant consumers of chip area in today’s processors. Correctness and high performance of arithmetic circuits is routinely expected and episodes such as the Intel Pentium division bug are indeed rare. The preceding context is changing due to several factors. First, at very high clock rates, the interfaces between arithmetic circuits and the rest of the processor become critical. Arithmetic units can no longer be designed and verified in isolation. Rather, an integrated design optimization is required which makes the development even more complex and costly. Second, optimizing arithmetic circuits to meet design goals by taking advantage of the strengths of new technologies, and making them tolerant to the weaknesses, requires a reexamination of existing design paradigms. Finally, Incorporation of higher-level arithmetic primitives into hardware makes the design, optimization, and verification efforts highly complex and interrelated. This is why computer arithmetic is alive and well today. Designers and researchers in this area produce novel structures with amazing regularity. A case in point is carry-lookahead adders. We used to think, in the not so distant past, that we know all there is to know about carry-lookahead fast adders. Yet, new designs, improvements, and optimizations are still appearing as of this writing. The ANSI/IEEE standard floating-point format has removed many of the concerns with compatibility and error control in floating-point computations, thus resulting in new designs and products with mass-market appeal. Given the arithmetic-intensive nature of many novel application areas (such as encryption, error checking, and multimedia), computer arithmetic will continue to thrive for years to come. The
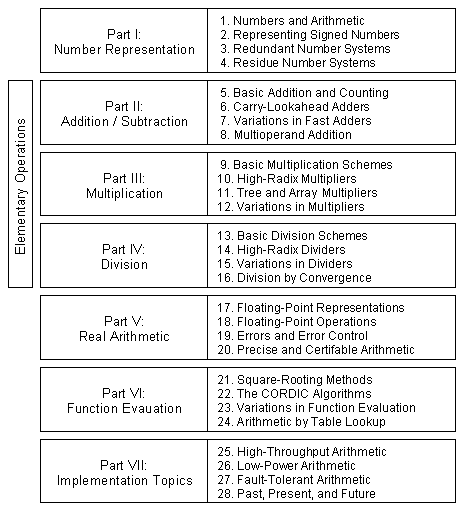
goals and structure of this book The field of computer arithmetic has matured to the point that a dozen or so texts and reference books have been published. Some of these books that cover computer arithmetic in general (as opposed to special aspects or advanced/unconventional methods) are listed at the end of this preface. Each of these books has its unique strengths and has contributed to the formation and fruition of the field. The current text, Computer Arithmetic: Algorithms and Hardware Designs, is an outgrowth of lecture notes that the author has developed and refined over many years. Here are the most important features of this text in comparison to the listed books: a. Division of material into lecture-size chapters: In my approach to teaching, a lecture is a more or less self-contained module with links to past lectures and pointers to what will transpire in future. Each lecture must have a theme or title and must proceed from motivation, to details, to conclusion. In designing the text, I have strived to divide the material into chapters, each of which is suitable for one lecture (1-2 hours). A short lecture can cover the first few subsections while a longer lecture can deal with variations, peripheral ideas, or more advanced material near the end of the chapter. To make the structure hierarchical, as opposed to flat or linear, lectures are grouped into seven parts, each composed of four lectures and covering one aspect of the field (Fig. P.1). b. Emphasis on both the underlying theory and actual hardware designs: The ability to cope with complexity requires both a deep knowledge of the theoretical underpinnings of computer arithmetic and examples of designs that help us understand the theory. Such designs also provide building blocks for synthesis as well as reference points for cost-performance comparisons. This viewpoint is reflected, e.g., in the detailed coverage of redundant number representations and associated arithmetic algorithms (Chapter 3) that later lead to a better understanding of various multiplier designs and on-line arithmetic. Another example can be found in Chapter 22 where CORDIC algorithms are introduced from the more intuitive geometric viewpoint. c. Linking computer arithmetic to other subfields of computing: Computer arithmetic is nourished by, and in turn nourishes, other subfields of computer architecture and technology. Examples of such links abound. The design of carry-lookahead adders became much more systematic once it was realized that the carry computation is a special case of parallel prefix computation which had been extensively studied by researchers in parallel computing. Arithmetic for/by neural networks is an area that is still being explored. The residue number system has provided an invaluable tool for researchers interested in complexity theory and limits of fast arithmetic as well as to the designers of fault-tolerant systems. d. Wide coverage of important topics: The current text covers virtually all important algorithmic and hardware design topics in computer arithmetic, thus providing a balanced and complete view of the field. Coverage of unconventional number representation methods (Chapters 3-4), arithmetic by table-lookup (Chapter 24), which is becoming increasingly important, multiplication and division by constants (Chapters 9 and 13), errors and certifiable arithmetic (Chapters 19-20), and the topics in Part VII (Chapters 25-28) do not all appear in other textbooks. e. Unified and consistent notation/terminology throughout the text: Every effort is made to use consistent notation/terminology throughout the text. For example, r always stands for the number representation radix and s for the remainder in division or square-rooting. While other authors have done this in the basic parts of their texts, there is a tendency to cover more advanced research topics by simply borrowing the notation and terminology from the reference source. Such an approach has the advantage of making the transition between reading the text and the original reference source easier, but it is utterly confusing to the majority of the students who rely on the text and do not consult the original references except, perhaps, to write a research paper. Summary
of topics The seven parts of this book, each composed of four chapters, have been written with the following goals: Part I sets the stage, gives a taste of what is to come, and provides a detailed perspective on the various ways of representing fixed-point numbers. Included are detailed discussions of signed numbers, redundant representations, and residue number systems. Part II covers addition and subtraction that form the most basic arithmetic building blocks and are often used in implementing other arithmetic operations. Included in the discussions are addition of a constant (counting), various methods for designing fast adders, and multi-operand addition. Part III deals exclusively with multiplication, beginning with the basic shift-add algorithms and moving on to high-radix, tree, array, bit-serial, modular, and a variety of other multipliers. The special case of squaring is also discussed. Part IV covers division algorithms and their hardware implementations, beginning with the basic shift-subtract algorithms and moving on to high-radix, pre-scaled, modular, array, and convergence dividers. Part V deals with real number arithmetic, including methods for representing real numbers, floating-point arithmetic, representation/computation errors, and methods for high-precision and certifiable arithmetic. Part VI covers function evaluation, beginning with the important special case of square-rooting and moving on to CORDIC algorithms followed by general convergence and approximation methods, including the use of lookup tables. Part VII deals with broad design and implementation topics, including pipelining, low-power arithmetic, and fault tolerance. This part concludes by providing historical perspective and examples of arithmetic units in real computers. Pointers
on how to use the book For classroom use, the topics in each chapter of this text can be covered in a lecture of duration 1-2 hours. In my own teaching, I have used the chapters primarily for 1.5-hour lectures, twice a week, in a 10-week quarter, omitting or combining some chapters to fit the material into 18-20 lectures. But the modular structure of the text lends itself to other lecture formats, self-study, or review of the field by practitioners. In the latter two cases, the readers can view each chapter as a study unit (for one week, say) rather than as a lecture. Ideally, all topics in each chapter should be covered before moving to the next chapter. However, if fewer lecture hours are available, then some of the subsections located at the end of chapters can be omitted or introduced only in terms of motivations and key results. Problems of varying complexities, from straightforward numerical examples or exercises to more demanding studies or mini-projects, have been supplied for each chapter. These problems form an integral part of the book and have not been added as afterthoughts to make the book more attractive for use as a text. A total of 464 problems are included (15-18 per chapter). Assuming that two lectures are given per week, either weekly or biweekly homework can be assigned, with each assignment having the specific coverage of the respective half-part (two chapters) or full-part (four chapters) as its “title”. An instructor’s manual, with problem solutions and enlarged versions of the diagrams and tables, suitable for reproduction as transparencies, is planned. The author’s detailed syllabus for the course ECE 252B at UCSB is available at the author’s Web page (look under “Teaching and Textbooks”). A simulator for numerical experimentation with various arithmetic algorithms is available at the following Web site, courtesy of Professor Israel Koren: References to classical papers in computer arithmetic, key design ideas, and important state-of-the-art research contributions are listed at the end of each chapter. These references provide good starting points for doing in-depth studies or for preparing term papers/projects. A large number of classical papers and important contributions in computer arithmetic have been reprinted in [Swar90]. New ideas in the field of computer arithmetic appear in papers presented at bi-annual conferences, known as ARITH-n, held in odd-numbered years [Arit]. Other conferences of interest include Asilomar Conference on Signals, Systems, and Computers [Asil], International Conference on Circuits and Systems [ICCS], Midwest Symposium on Circuits and Systems [MSCS], and International Conference on Computer Design [ICCD]. Relevant journals include IEEE Transactions on Computers [TrCo], particularly its special issues on computer arithmetic, IEEE Transactions on Circuits and Systems [TrCS], Computers & Mathematics with Applications [CoMa], IEE Proceedings: Computers and Digital Techniques [PrCD], IEEE Transactions on VLSI Systems [TrVL], and Journal of VLSI Signal Processing [JVSP]. Acknowledgments The current text, Computer Arithmetic: Algorithms and Hardware Designs, is an outgrowth of lecture notes that the author has used for the graduate course “ECE 252B: Computer Arithmetic” at the University of California, Santa Barbara, and, in rudimentary forms, at several other institutions prior to 1988. The text has benefited greatly from keen observations, curiosity, and encouragement of my many students in these courses. A sincere thanks to all of them! General
references
[Arit] International Symposium on Computer Arithmetic, Sponsored by IEEE Computer Society. This series began with a one-day workshop in 1969 and was subsequently held in 1972, 1975, 1978, and in odd-numbered years since 1981. The 13th symposium in the series, ARITH-13, was held on July 6-9, 1997, in Asilomar, CA. ARITH-14 is planned for Apr. 14-16, 1999, in Adelaide, Australia. [Asil] Asilomar Conference on Signals Systems, and Computes, sponsored annually by IEEE and held on the Asilomar Conference Grounds in Pacific Grove, CA. The 32nd conference in this series was held on November 1-4, 1998. [Cava84] Cavanagh, J.J.F., Digital Computer Arithmetic: Design and Implementation, McGraw-Hill, 1984. [CoMa] Computers & Mathematics with Applications, journal published by Pergamon Press. [Flor63] Flores, I., The Logic of Computer Arithmetic, Prentice Hall, 1963. [Gosl80] Gosling, J.B., Design of Arithmetic Units for Digital Computers, Macmillan, 1980. [Hwan79] Hwang, K., Computer Arithmetic: Principles, Architecture, and Design, Wiley, 1979. [ICCD] International Conference on Computer Design, sponsored annually by the IEEE Computer Society. ICCD-98 was held on October 4-7, 1998, in Austin, TX. [ICCS] International Conference on Circuits and Systems, sponsored annually by the IEEE Circuits and Systems Society. The latest in this series was held on May 31 – June 3, 1998, in Monterey, CA. [JVSP] J. VLSI Signal Processing, published by Kluwer Academic Publishers. [Knut81] Knuth, D.E., The Art of Computer Programming -- Vol. 2: Seminumerical Algorithms, Addison-Wesley, 3rd Edition, 1997. [Kore93] Koren, I., Computer Arithmetic Algorithms, Prentice Hall, 1993. [Kuli81] Kulisch, U.W. and W.L. Miranker, Computer Arithmetic in Theory and Practice, Academic Press, 1981. [MSCS] Midwest Symposium on Circuits and Systems, sponsored annually by the IEEE Circuits and Systems Society. This series of symposia began in 1955, with the 41st in the series held on August 9-12, 1998, in Notre Dame, IN. [Omon94] Omondi, A.R., Computer Arithmetic Systems: Algorithms, Architecture and Implementation, Prentice Hall, 1994. [PrCD] IEE Proc.: Computers and Digital Techniques, journal published by the Institution of Electrical Engineers, United Kingdom. [Rich55] Richards, R.K., Arithmetic Operations in Digital Computers, Van Nostrand, 1955. [Scot85] Scott, N.R., Computer Number Systems and Arithmetic, Prentice Hall, 1985. [Stei71] Stein, M.L. and W.D. Munro, Introduction to Machine Arithmetic, Addison-Wesley, 1971. [Swar90] Swartzlander, E.E., Jr., Computer Arithmetic, 2 Vols., IEEE Computer Society Press, 1990. [TrCo] IEEE Trans. Computers, journal published by the IEEE Computer Society. Occasionally devotes entire special issues or sections to computer arithmetic, e.g.: Vol. 19, No. 8, Aug. 1970; Vol. 22, No. 6, June 1973; Vol. 26, No. 7, July 1977; Vol. 32, No. 4, Apr. 1983; Vol. 39, No. 8, Aug. 1990; Vol. 41, No. 8, Aug. 1992; Vol. 43, No. 8, Aug. 1994; Vol. 47, No. 7, July 1998. [TrCS] IEEE Trans. Circuits and Systems -- II: Analog and Digital Signal Processing, journal published by IEEE. [TrVL] IEEE Trans. Very Large Scale Integration (VLSI) Systems, journal published jointly by the IEEE Circuits and Systems Society, Computer Society, and Solid-State Circuits Council. [Wase82] Waser, S. and M.J. Flynn, Introduction to Arithmetic for Digital Systems Designers, Holt, Rinehart, & Winston, 1982. [Wino80] Winograd, S., Arithmetic Complexity of Computations, SIAM, 1980.
Return to: Top of this page Contents at a Glance
Fig.
0.1. The structure of this book in
parts and chapters.
Return to: Top of this page Book Reviews Review
of: Computer Arithmetic: Algorithms and Hardware Designs (B. Parhami,
Oxford) Appeared
in ACM Computing Reviews, Oct. 1999 Reviewer:
Peter Turner Computer
arithmetic (G.1.0), General (B.2.0 …), Algorithms, Design This
well-organized text for a course in computer arithmetic at the senior
undergraduate or beginning graduate level is divided into seven parts, each
comprising four chapters. Each part is intended to occupy one or two lectures.
The book has clearly benefited from the author’s experience in teaching this
material. It achieves a nice balance among the mathematical development of
algorithms and discussion of their implementation. Each
chapter has 15 or more exercises, of varying difficulty and nature, and its own
references. I would have liked to see a comprehensive bibliography for the whole
book as well, since this could include items that are not specifically referred
to in the text. The
first four parts are devoted to number representation, addition and subtraction,
multiplication, and division. These are concerned with integer (or at least
fixed-point) arithmetic. The next two parts deal with real arithmetic and
function evaluation. The final part, “Implementation Topics,” covers some
practical engineering aspects. Part
1 has chapters titled “Numbers and Arithmetic,” “Representing Signed
Numbers,” “Redundant Number Systems,” and “Residue Number Systems.”
The first begins with a brief history of the Intel division bug, which serves to
introduce the significance of computer arithmetic. A second “motivating
example” is based on high-order roots and powers. The primary content
describes fixed-radix number systems and radix conversion. It is typical of the
book that these sections contain many well-chosen examples and diagrams. The
chapter on signed numbers covers the expected material: sign-magnitude, biased,
and complemented representations, including the use of signed digits. Redundant
number systems are introduced within the discussion of carry propagation. The
mathematical basis for carry-free addition is discussed along with its
algorithm. Residue number systems are discussed, beginning with the
representation and the choice of moduli. The explanation of conversion to and
from the binary system includes a good description of the Chinese remainder
theorem. Part
2, on addition and subtraction, begins with the basics of half and full adders,
and carry-ripple adders. This motivates the chapter on carry-lookahead adders.
The basic idea and its implementation are presented well. This chapter finishes
with a short section on VLSI implementation, which gives pointers to further
study. Similar sections appear in most chapters. Variations on the
carry-lookahead theme are the subject of the next chapter, while Wallace and
Dadda trees of carry-save adders are the final addition topics. This provides a
natural link to multiplication. The
basic structure of parts 3 and 4 (on multiplication and division) is the same.
There are chapters on basic and high-radix multiplication and division. Tree and
array multipliers, and special variations (for squaring and multiply-accumulate)
complete the multiplication part. The final chapter on division covers
Newton-like methods. One of my few criticisms of the book is that the
explanation of SRT and digit selection could be more extensive. A student
unfamiliar with these topics might have difficulty gaining a full understanding
of this important technique. Part
5 is concerned with real arithmetic, and the floating-point system in
particular. The chapter on real-number representation includes a brief section
on logarithmic arithmetic, which offers the student a glimpse of alternatives.
Other schemes such as Hamada’s “Universal Representation of Real Numbers”
or symmetric level-index could also have been mentioned here. Floating-point
arithmetic is described using the integer operations. Rounding and normalization
are also discussed. Chapter 19 is a short chapter on errors and their control,
which covers most of the basics without giving all the details. For a
mathematics course on computer arithmetic, this chapter would need expanding.
The final chapter on real arithmetic describes continued fraction, multiple
precision, and interval arithmetic. Part
6 covers function evaluation, with chapters on square-rooting, CORDIC
algorithms, variations (iterative methods and approximations), and table lookup.
Each chapter describes the basic ideas well and provides a sufficient taste of
its subject matter to point the interested student to further study. The
description of the CORDIC algorithms is more complicated than necessary. Use of
an elementary trigonometric identity would simplify some of the formulas
substantially. The use of degrees in the introduction to the CORDIC algorithm is
also a dubious choice. The
final part has chapters on high-throughput, low-power, and fault-tolerant
arithmetic. Each is fairly brief but would serve as an introduction to some of
the practical engineering aspects of computer arithmetic. Overall, Parhami has done an excellent job of presenting the fundamentals of computer arithmetic in a well-balanced, careful, and organized manner. The care taken by the author is borne out by the almost total absence of typos or incorrect cross-references. I would choose this book as a text for a first course in computer arithmetic. Return to: Top of this page Complete
Table of Contents Note: Each chapter ends with problems and references. Part I Number Representation1 Numbers and Arithmetic
2 Representing Signed Numbers
3 Redundant Number Systems
4 Residue Number Systems
Part II Addition/Subtraction5 Basic Addition and Counting
6 Carry-Lookahead Adders
7 Variations in Fast Adders
8 Multi-Operand Addition
Part III Multiplication9 Basic Multiplication Schemes
10 High-Radix Multipliers
11 Tree and Array Multipliers
12 Variations in Multipliers
Part IV Division13 Basic Division Schemes
14 High-Radix Dividers
15 Variations in Dividers
16 Division by Convergence
Part V Real Arithmetic17 Representing the Real Numbers
18 Floating-Point Arithmetic
19 Arithmetic Errors and Error Control
20 Precise and Certifiable Arithmetic
Part VI Function Evaluation21 Square-Rooting Methods
22 The CORDIC Algorithms
23 Variations in Function Evaluation
24 Arithmetic by Table Lookup
Part VII Implementation Topics25 High-Throughput Arithmetic
26 Low-Power Arithmetic
27 Fault-Tolerant Arithmetic
28 Past, Present, and Future
IndexReturn to: Top of this page From
the Preface to the Instructor’s Manuals This instructor’s manual consists of two volumes. Volume 1 presents solutions to selected problems and includes additional problems (many with solutions) that did not make the cut for inclusion in the text Computer Arithmetic: Algorithms and Hardware Designs (Oxford University Press, 2000) or that were designed after the book went to print. Volume 2 contains enlarged versions of the figures and tables in the text as well as additional material, presented in a format that is suitable for use as transparency masters. Volume 1, which consists of the following parts, is available to qualified instructors through Oxford University Press in New York: Volume 1 Part I Selected solutions and additional problems Part II Question bank, assignments, and projects Volume 2, which consists of the following parts, is available as a large downloadable file through the book’s Web page (see Presentations): Volume 2 Parts I-VII Lecture slides and other presentation material The book’s Web page, given below, also contains an errata and a host of other material (please note the upper-case “F” and “P” and the underscore symbol after “text” and “comp”: http://www.ece.ucsb.edu/Faculty/Parhami/text_comp_arit.htm The author would appreciate the reporting of any error in the textbook or in this manual, suggestions for additional problems, alternate solutions to solved problems, solutions to other problems, and sharing of teaching experiences. Please e-mail your comments to or send them by regular mail to the author’s postal address: Department of Electrical and Computer Engineering University of California Santa Barbara, CA 93106-9560, USA Contributions will be acknowledged to the extent possible.
Return to: Top of this page Presentations The following PowerPoint and PDF presentations for the seven parts of the text are available (file sizes 0.8 to 1.2 MB):
Additionally, the following versions of the Instructor's Manual, Vol. 2, are available, but they have been superseded by the presentations above:
Return to: Top of this page Errors
and Additions (updated with a few 4th-printing errors beginning on 2003/12/16) The following additions and corrections are presented in the order of page numbers in the book. Each entry is assigned a unique code, which appears in square brackets and begins with the date of posting or last modification in the format "yymmdd". A previous version of this page stated that some errors have been corrected in the second printing. However, due to an oversight, the submitted corrections were not made; so errors are identical in the first and second printings of the book. To the author's dismay, even the third printing of the book contained many of these errors; additionally, the author discovered in December 2002 that a number of new errors were introduced in the third printing. All corrections, and many of the additions, were incorporated into the fourth printing of the book. The notation "<j" at the end of the code in brackets means that the correction or addition has been incorporated in printings j and higher; i.e., it applies only the printings j – 1 and lower. Codes ending with "=3" mark errors specific to the third printing. Note: To find out which printing of the book you own, look at the bottom of the copyright page; there, you see a sequence of digits "9 8 7 . . .", the last of which designates the printing.
p. xix [001207<4] In line 17 (middle of the page), change the link for the author's detailed syllabus for the course ECE 252B to: http://www.ece.ucsb.edu/Faculty/Parhami/ece_252b.htm p. xix [001207a<4] In line 20 (middle of the page), change the link for Professor Koren's arithmetic simulator to: http://www.ecs.umass.edu/ece/koren/arith/simulator/ p. xix [001205<4] In line 21 (middle of the page), change "Pofessor" to "Professor". p. xx [030425c<4] Change the last two sentences in the reference [Arit] to: The 15th symposium in the series, ARITH-15, was held on June 11-13, 2001, in Vail, Colorado. ARITH-16 was held June 15-18, 2003, in Santiago de Compostela, Spain. p. xx [001205a<4] At the end of the reference [TrCo], add the new special issue: Vol. 49, No. 7, July 2000. p. 4 [021009<4] In line 6, change "worse that what is" to "worse than what is". p. 8 [010212<4] In the first display equation near the beginning of Section 1.4, the upper bound of summation should be k – 1, not k. p. 15 [021118a<4] In part a of Problem 1.4, change "unsigned binary integer" to "unsigned nonzero binary integer." p. 15 [030423<3] In part c of Problem 1.4, the summation symbols should be followed by “even i” (insert space) and “odd i” (i is not a subscript for odd). p. 21 [030423a<3] In the caption to Fig. 2.2, change “pre-complementation” to “precomplementation”. p. 21 [061201] In the last two lines of the second paragraph of Section 2.2, change the exponents k to k - 1 (two instances). p. 23 [030423b<3] Remove the period from the end of the caption for Table 2.1. p. 27 [030423c<3] In Fig. 2.7, change “y or y^c” to “y or y^compl” (the symbol "^" indicates superscript). p. 29 [051003] In line 8, the the last index should be -l (minus ell) rather than -1. p. 29 [021009a<4] In line 10 from bottom, the upper bound of the summation should be k – 1 instead of k. p. 31 [011013<4] Change the title of Problem 2.1 to "Signed-magnitude adder/subtractor". p. 32 [030423d<3] At the very beginning of Problem 2.12, change “Range” to “Range and precision”. p. 40 [010129<4] On line 6 of Example 3.3, change "20 (carry 1)" to "20 (carry 2)". p. 50 [001205g<4] At the end of part a of Problem 3.1, add: “Do not just refer to the results in [Parh90]; rather, provide your own proof. p. 51 [010130<4] Add the following to the end of part c in Problem 3.6: "or show that such a procedure is impossible." p. 59 [051003a] In line 18, first display equation, the first superscript after RNS should be ak-1, not ak-2. p. 67 [030421<4] Change caption of Fig. 4.3 to read: Adding a 4-bit ordinary mod-13 residue x to a 4-bit pseudoresidue y, producing a 4-bit mod-13 pseudoresidue z. p. 67 [030421a<4] On line 2, change "Addition of such pseudoresidues" to read: Addition of such a pseudoresidue y to an ordinary residue x, producing a pseudoresidue z, p. 67 [030421b<4] Add the end of the first paragraph add: Addition of two pseudoresidues is possible in a similar way [Parh01]. p. 71 [031216] In the statement of Problem 4.9, change both occurrences of m to M (the dynamic range of RNS). p. 72 [030421c<4] Add the following reference: [Parh01] Parhami, B., “RNS Representations with Redundant Residues,” Proc. 35th Asilomar Conf. Signals, Systems, and Computers, Nov. 2001, pp. 1651-1655. p. 87 [001205h<4] In Fig. 5.13a, for the switch controlled by p_i, the contact labels 0 and 1 should be interchanged. p. 99 [030423e<3] In line 4, replace “(g_k–2, p_k–1)” by “(g_k–2, p_k–2)”. p. 100 [030423f<3] In the last line, replace “thoughthe” by “though the” (insert space). p. 103 [021009b<4] In Fig. 6.13, last line of text has a redundant comma between a closed bracket and open parenthesis. p. 104 [030423g] At the end of Section 6.6, add a new paragraph: Various parallel-prefix adders, all with minimum-latency designs when only node delays are considered, may turn out quite different when the effects of interconnects (including fan-in, fan-out, and signal propagation delay on wires) are considered [Know99], [Huan00], [Beau01]. p. 105 [030423h<3] At the end of part a of Problem 6.6, add: “Then present expressions for these signals in terms of g and p signals of nonoverlapping subblocks such as [i_0, i_1 – 1] and [i_1, j_0].” p. 106 [030423j<3] In part a of Problem 6.10, change “c_0 = 0” to “c_0 = 1”. p. 107 [030423m<3] Add [Kogg73] to the reference list for Chapter 6. [Kogg73] Kogge, P.M. and H.S. Stone, “A Parallel Algorithm for the Efficient Solution of a General Class of Recurrences,” IEEE Trans. Computers, Vol. 22, pp. 786-793, 1973. p. 107 [030423k] Add the following references: [Know99] Knowles, S., “A Family of Adders,” Proc. Symp. Computer Arithmetic (ARITH-14), 1999, printed at the end of ARITH-15 Proceedings, 2001, pp. 277-284. [Huan00] Huang, Z. and M.D. Ercegovac, “Effect of Wire Delay on the Design of Prefix Adders in Deep-Submicron Technology,” Proc. 34th Asilomar Conf. Signals, Systems, and Computers, Oct. 2000, pp. 1713-1717. [Beau01] Beaumont-Smith, A. and C.-C. Lim, “Parallel Prefix Adder Design,” Proc. 15th Symp. Computer Arithmetic, Vail, CO, June 2001, pp. 218-225. p. 113 [030423n<3] In Fig. 7.7b, the second block from the left should be labeled “Block E”, not “Block B”. p. 115 [041014] On line 3, change "that the ripple-carry scheme" to "than the ripple-carry scheme." p. 119 [010929] At the beginning of the second paragraph, change "Our final hybrid adder" to "Another hybrid adder". p. 119 [030423p] (Between the second and third paragraphs, add the following new paragraph:) A hybrid adder may use more than two different schemes. For example, the 64-bit adder in the Compaq/DEC Alpha 21064 microprocessor is designed using four different methods [Dobb92]. At the lowest level, 8-bit Manchester carry chains are employed. The lower 32-bits of the sum are derived via carry lookahead at the second level, while conditional-sum addition is used to obtain two versions of the upper 32 bits. Carry-select is used to pick the correct version of the sum's upper 32 bits. p. 121 [010208<4] In Problem 7.4, part b, change "two-level-skip" to "two-level carry-skip". p. 121 [031216a] In Problem 7.6, at the end of the introductory sentence, ending with "adders," add "so as to reduce the overall latency." p. 123 [030423q<3] In part c of Problem 7.18, replace “(4 ´ 8)-bit” by “4 ´ (8-bit)” and “(2 ´ 16)-bit” by “2 ´ (16-bit)”. p. 124 [030423r] Add the following reference: [Dobb92] Dobberpuhl, D. et al, “A 200 MHz 64-b Dual-Issue CMOS Microprocessor,” IEEE J. Solid-State Circuits, Vol. 27, No. 11, Nov. 1992. p. 126 [030423s<3] In the left panel of Fig. 8.1, the heavy dots should be aligned vertically as in Fig. 9.1. p. 126 [030504=3] In the left panel of Fig. 8.1, the row of dots labled "x" should be preceded by a multiplication sign. p. 129 [011001b<4] In Fig. 8.8, the rightmost box (rectangle) should have only two dots in it; remove the bottom dot. p. 129 [030423t<3] In line 3 (after the figures), replace “(n – 1)C_CSA” by “(n – 2)C_CSA”. p. 134 [011001c<4] In Fig. 8.15, the next to the last horizontal dashed line must be extended to the right. Also, the vertical alignment of the dots needs improvement. p. 155 [030423u<3] Parts d, e, and f of Problem 9.14 should be parts e, f, and g. p. 158 [010927<4] In Fig. 10.1, the four "x" terms in parentheses, with subscripts 0, 1, 2, and 3, must be italicized. p. 161 [031216b] In Fig. 10.6, the left (0) input of the multiplexer should be shown as sign-extended, not extended with a 0 bit. p. 164 [010927a<4] In Fig. 10.10, right below the box labeled "Selective complement", the letters "a" must be italicized (four instances). p. 179 [030423v<3] Line 5 in the partial products bit-matrix (between the two horizontal lines) of Fig. 11.8c should change to a4x4, -a3x4, -a2x4, -a1x4, -a0x4 (i.e., the four overbars should be shifted to the next symbols to the right). p. 206 [031216c] In the statement of Problem 12.9, the introductory paragraph should end with 2k – 2j – 1 (not 2k – 2j + 1) p. 215 [030423w<3] On lines 1 and 2, k should be italicized (2k-bit, k-bit). p. 215 [030423x<4] The last line "d_done:" of the program in Fig. 13.4 should move up, so that it appears before the line labeled "d_by_0". p. 220 [021211<4] On line 10 from bottom, replace "if needed" by "needed when sign(s^(k)) ¹ sign (z)". p. 221 [021211a<4] In the right-hand comments of Fig. 13.9, line 7 from the bottom (just above "corrective subtraction"), change "sign(s^(4)) ¹ sign (d)" to "sign(s^(4)) ¹ sign (z)". p. 221 [030425p<3] In the right-hand comments of Fig. 13.9, line 4 from the bottom, change “Ucorrected” to “Uncorrected”. p. 224 [030423y<3] In Fig. 13.11b, 2k ´ k should be 2k / k. p. 224 [030504a=3] In Fig. 13.11a, the row of dots labeled "x" should be preceded by a multiplication sign. p. 225 [050107] In Problem 13.7 (all four parts), change the magnitude of d to .1101 (i.e., change the first bit after the radix point from 0 t0 1) to obviate the need for an initial adjustment to avoid overflow. p. 230 [030421d<4] On line 13, cite the reference [Nadl56] at the end of the sentence "... speed up the iterations in binary division." p. 233 [021118<4] In Fig. 14.6, 2s^(2) is not < –1/2 as stated; rather, it is in [–1/2, 0). So, that line in the figure, and the next four lines, should change as follows. Beginning with s^(4), the values are correct, but in the first line associated with s^(4), “= 2s^(3)” is redundant and should be removed.
2s^(2) 1.1010 1 in [-1/2, 1/2), so set q_-3 = 0 ----------------------------- s^(3) = 2s^(2) 1.1010 1 2s^(3) 1.0101 < -1/2, so set q_-4 = -1 +d 0.1010 and add ----------------------------- s^(4) 1.1111 Negative
Obviously, the uncorrected BSD quotient (next to last line of figure) should change to 0.100-1. p. 234 [001211f<4] In the next to the last line of text, the middle interval should be [–1/2, 0); i.e., insert minus sign. p. 236 [030421s<4] In Fig. 14.4, the labels d and d-bar of the multiplexer just below the d register should be switched (the 0 input should be labeled d-bar and the 1 input d). p. 239 [020320<4] In line 5 after Fig. 14.12, change "4 bits of p" to "5 bits of p". p. 242 [011013b<4] In Problem 14.4, all four parts, replace the magnitude of d with .1010 (this will make z smaller than d in magnitude, thus obviating the need for initial scaling). p. 245 [030421e<4] Add the following reference: [Nadl56] Nadler, M., "A High-Speed Electronic Arithmetic Unit for Automatic Computing Machines," Acta Technica (Prague), No. 6, pp. 464-478, 1956. p. 248 [030423z<3] Italicize the “r” and “d” in the lower right corner of Fig. 15.3. p. 248 [030424=3] This error applies only to the 3rd printing. For some unknown reason, all the occurrences of the Greek letters a and b have been dropped. Alpha should be inserted in the numerator of the fraction that follows "Note: h =". Beta should be inserted in the four formula at the right edge of the figure, between two plus signs or between plus sign and closed parenthesis. Beta should also be inserted just before "+ 1" to the left of the upper double-headed arrow. Additionally, two tiles (boxes) below each of the steps shown in heavy line should be labeled with b and two boxes above each step should be labeled with b + 1. The box with heaviest shading remains unlabeled. [phew!!] p. 248 [020320a<4] In the last two lines of Section 15.1, change "3 + 3 + 4 = 10" to "4 + 4 + 4 = 12" and "4 + 4 + 3 = 11" to "5 + 5 + 3 = 13". p. 249 [030424a<3] Make the following changes in Fig. 15.4: Below the horizontal axis, change “dmin + d” to “dmin + Dd”. Next to the vertical axis, near the middle, change “p” to “Dp”. Next to the vertical axis, change “(h + – 1)” to “(h + a – 1)” and “(–h + )” to “(–h + a)”. In the shaded region, above the dotted horizontal arrow, change “d” to “Dd”. Next to the curved inner arrow, just above the shaded region, insert “a”. Next to the curved outer arrow, just below the shaded region, change “1” to “a – 1”. In upper right corner, change “(h + – 1)” to “(h + a – 1)” and “(–h + )” to “(–h + a)”. p. 251 [030424b<3] In the lightly shaded region of Fig. 15.6, near its left edge, change the “integral sign” to “*”. p. 251 [030424c=3] This error applies only to the 3rd printing. In Fig. 15.6, all boxes above the staircase (heavy line) that are labeled b should be labeled b + 1. p. 253 [010924<4] At the bottom right of Fig. 15.7, the words “dividend” and “quotient” should not be italicized. p. 258 [030424d<3] Problem 15.13 has no part c. Make parts d-i into parts c-h. p. 270 [030424e] At the end of Section 16.5, add the following paragraph: There are other ways to avoid multiple iterations besides starting with a very precise estimate for 1/d. An interesting scheme has been proposed by Ito, Takagi, and Yajima [Ito97] and refined by Matula [Matu01]. Let d = D + 2–if, where D is d truncated to i fractional bits and f is a fraction. By complementing the bits of d beyond the ith fractional bit, we get e = D + 2–i(1 – f). The inverse of de = D2 + 2–iD + 2–2if(1 – f) is computed easily via low-precision table lookup (and with even smaller tables if a bipartite table scheme is used) because it has a small dependency on f. If the approximate inverse of de is c, then z/d is obtained by rounding (ze)c for single precision and (ze)c[2 – (de)c] for double precision. This type of scaling of a number so that its inverse is more easily found has also been used in a method due to Ercegovac et al [Erce00]. p. 274 [030421f<4] In the statement of Problem 16.10, replace "f:" and the formula following it with: f [Pozr98]: x(i+1) = x(i) – [f(x(i))/f¢(x(i))] [1 + f(x(i))f²(x(i))/(2f¢2(x(i)))] p. 275 [030421g<4] Add the reference: [Pozr98] Pozrikidis, C., Numerical Computation in Science and Engineering, Oxford, 1998, p. 203. p. 275 [030424f] Add the following references: [Erce00] Ercegovac, M.D., T. Lang, J.-M. Muller, and A. Tisserand, “Reciprocation, Square Root, Inverse Square Root, and Some Elementary Functions Using Small Multipliers,” IEEE Trans. Computers, Vol. 49, No. 7, pp. 628-637, July 2000. [Ito97] Ito, M., N. Takagi, and S. Yajima, “Efficient Initial Approximation for Multiplicative Division and Square Root by a Multiplication with Operand Modification,” IEEE Trans. Computers, Vol. 46, No. 4, pp. 495-498, Apr. 1997. [Matu01] Matula, D.W., “Improved Table Lookup Algorithms for Postscaled Division,” Proc. 15th Symp. Computer Arithmetic, Vail, CO, June 2001, pp. 101-108. p. 283 [001211<4] Change the next to the last sentence "This . . . support denormals." to: Because this "graceful underflow" provision can lead to cost and speed overhead in hardware, many implementations of the standard do not support denormals, opting instead for the faster “flush to zero” mode. p. 286 [030421t<4] Near the end of the first paragraph, delete "or underflow." p. 286 [001211a<4] In line 21, appearing just after the list of the four rounding modes, remove "are optional and". p. 291 [001211b<4] At the end of line 3, change "optional" to "required". p. 292 [030424g<3] In the last line (just before Fig. 17.13), the denominator of the fraction should be “±2^e2”. p. 299 [010924a<4] In Fig. 18.1, a gray control line must be connected from the bottom of the "Sign logic" box to the left side of the "Round and selective complement" box. (This is to signal when the result must be complemented.) p. 299 [030424h<3] In line 5 after the figure, change “special operands” to “special outcomes”. p. 301 [030424j<3] On the left edge of Fig. 18.3, all of the slanted lines should be shortened so that their ends are vertically aligned (as on the right edge of the same figure). p. 303 [030424k] (At the end of Section 18.2, add the following paragraph:) Given that a preshift of 2 or more bits rules out the possibility of requiring a multiple-bit postshift to remove leading 0s or 1s, very fast floating-point adders use a dual datapath design. When the exponents differ by no more than 1, the operands are routed to a datapath that contains a leading 0s/1s predictor and a full postshifter; in fact, one can even avoid rounding in this path. Otherwise, a datapath with a full preshifter and no postshifter is employed. Note that the 1-bit normalizing right shift that may be required can be combined with rounding. For a description of a modern processor that uses this approach, see [Nain01]. p. 305 [030421h<4] At the end of the next-to-last paragraph, ending with "in the final step" add: Alternatively, rounding can be converted to truncation through the injection of corrective terms during multiplication [Even00]. p. 311 [030421i<4] Add the reference: [Even00] Even, G. and P.-M. Seidel, “A Comparison of Three Rounding Algorithms for IEEE Floating-Point Multiplication,” IEEE Trans. Computers, Vol. 49, No. 7, pp. 638-650, July 2000. p. 312 [030424m] Add the following reference: [Nain01] Naini, A., A. Dhablania, W. James, and D. Das Sarma, “1-GHz HAL SPARC64 Dual Floating Point Unit with RAS Features,” Proc. 15th Symp. Computer Arithmetic, Vail, CO, June 2001, pp. 173-183. p. 314 [021211b<4] In the last display equation, on line 8 from bottom, insert a negative sign before ulp/2 appearing to the right of "A = round". p. 316 [011003] (Immediately after Theorem 19.1, add the following proof:) The left-hand side of the inequality is just the worst-case effect of chopping that makes the result smaller than the exact value. The only way that the result can be larger than x + y is if we right-shift y by more than g digits, thus losing some of its digits and, hence, subtracting a smaller magnitude from x. The maximum absolute error in this case is less than r^(p + g). The right-hand side follows by noting that x + y is greater than 1/r^2: x is in [1/r, 1) and the shifted y has a magnitude of at most 1/(r^2), given that it has been shifted by at least two digits. p. 318 [030421j<4] In Example 19.4, add after the final formula: Kahan offers a thorough discussion in "Miscalculating Area and Angles of a Needle-like Triangle" ( http://www.cs.berkeley.edu/~wkahan/Triangle.pdf ). p. 326 [031216d] In the statement of Problem 19.15, change y to a positive number (remove the negative sign from -.555 ´ 10-1). p. 334 [030424n] (At the end of Section 20.3, add the following paragraph:) An alternative to building a new higher-precision floating-point format, and synthesizing the required operations from scratch using integer arithmetic, is to rely on multiple standard ANSI/IEEE numbers to represent numbers with greater precision. This approach is particularly suitable for building high-precision software packages that are to be run on conventional processors with standard floating-point hardware. For example, in a double-double (quad-double) format, two (four) double-precision numbers with different exponents are used whose sum is a desired high-precision number. Arithmetic algorithms for such numbers can be developed using conventional floating-point arithmetic operations on the component numbers. For details of the quad-double format and references to earlier work in this area, see [Hida01]. p. 337 [030424p<3] The right-hand side of the last formula in the statement of Theorem 20.1 should be: f(y^(1), y^(2), . . . , y^(n)) p. 338 [030424q] (At the end of the third paragraph in Section 2.6, add:) More recently, floating-point capabilities similar to those of MMX have been introduced in Intel processors [Thak99]. These are aimed at 3D and video applications that involve streaming data; data that is used only once (for geometric rendering) and then discarded. The parallel processing of fractional-precision data is sometimes referred to as subword parallelism (add index entry). For a review of media instruction sets, see [Kuro99]. p. 342 [011001d] Add the following reference: [Hida01] Hida, Y., X.S. Li, and D. Bailey, “Algorithms for Quad-Double Precision Floating Point Arithmetic,” Proc. 15th Symp. Computer Arithmetic, Vail, CO, June 2001, pp. 155-162. p. 342 [030424r] Add the following references: [Kuro99] Kuroda, I., “RISC, Video and Media DSPs,” Chap. 10 in Digital Signal Processing for Multimedia Systems, ed. by K.K. Parhi and T. Nishitani, Marcel Dekker, 1999, pp. 245-272. [Thak99] Thakkar, S. and T. Huff, “Internet Streaming SIMD Extensions,” IEEE Computer, Vol. 32, No. 12, pp. 26-34, Dec. 1999. p. 348 [001206i<4] In the equation for s^(j) on line 5, "2q^(–j)" should be changed to "2q^(j–1)". p. 350 [010927b<4] On line 2 of the second paragraph, in the string of 1s and -1s defining q, space must be inserted after the third, fifth, and sixth digits to make all digits equally spaced. p. 357 [030424s<3] In Fig. 21.7, add the label “1” to the diagonal input of the cell receiving z_–2 from above. p. 359 [030424t<3] Insert “[Parh99]” at the end of the sentence comprising part a of Problem 21.13. p. 360 [030424u<3] Add the following to the reference list:
Parhami, B., “Analysis of
the Lookup Table Size for Square-Rooting,” Proc.
33rd Asilomar Conf. Signals, Systems, and Computers, pp. 1327-1330, October
1999. p. 362 [010927c<4] On line 1 of the second paragraph, only the first letter of "rotations" should be in bold. p. 371 [030424v<3] Fix the vertical alignment of boxes at the lower right corner of Fig. 22.5; insert more space after text in the upper right corner. p. 371 [030424w=3] This error only applies to the 3rd printing; it is quite unfortunate that the error occurred in this Fig. 22.5 (symbols and Greek letters are missing) which is intended as a quick reference guide. In the top two boxes, rightward arrows should be inserted between z^(i) and 0 as well as between y^(i) and 0; i.e., these values tend to 0. In the leftmost column, m should be inserted before the first equal sign in each box (three instances). In the bottom box of the table, m should be inserted before the equal sign (i.e., m = -1). Finally, in the first of three equation lines at the bottom of the figure, m should be inserted in two places, right before d_i and immediately above K, and "set membership symbol" should be inserted before each of the two sets {-1, 0, 1} and {-1, 1}. p. 376 [001211i] Additional reference for CORDIC algorithms: [Dawi99] Dawid, H. and H. Meyr, “CORDIC Algorithms and Architectures,” Chap. 22 in Digital Signal Processing for Multimedia Systems, ed. by K.K. Parhi and T. Nishitani, Marcel Dekker, 1999, pp. 623-655. p. 377 [030425n<3] The last reference, [Phat99], is not placed properly in alphabetical order. p. 382 [010927d<4] On line 6 from the bottom, where the equation for e^x appears, a superscript (power) "2" should be inserted immediately after the parentheses enclosing e^s. p. 397 [030424x<4] Change the title of Section 24.3 to "BIT-SERIAL AND DISTRIBUTED ARITHMETIC". Also, modify the table of contents and add "Distributed arithmetic" to the index. p. 399 [030424y<3] In the large equation near the middle of the page, change “x” to “y” within each of the last two parenthesized expressions and add the missing open parenthesis in the superscript of the latter; i.e., change “i – 2)” to “(i – 2)”. p. 400 [030425] (At the end of Section 24.3, add the following:) When the structure of Fig. 24.3 is unrolled in time, so that the shift registers, the single table, and the adder are replicated, a scheme known as distributed arithmetic results [Whit89]. [add index entry] Distributed arithmetic has been found to be particularly efficient for implementing arithmetic circuits on field-programmable gate arrays (FPGAs). [add index entry] p. 403 [011002] In the next to the last line, change "two such methods" to "three such methods". p. 404 [030425a] (Just before the last paragraph beginning with "Our second example", add the following paragraph:) The example above is actually a variation and extension of the bipartite table [add index entry] method, first described by Das Sarma and Matula in connection with reciprocal approximation [DasS95]. In what follows, we describe the bipartite table method as our second example. Let the domain of interest for the evaluation of a function be divided into a number of intervals, each of which is further subdivided into smaller subintervals, with the number of subdivisions being a power of 2 in both cases. In this way, a high-order bits specify an interval, the next b bits specify a subinterval, and the remaining k – a – b bits identify a point in the subinterval. The trick is to use linear interpolation with an initial value determined for each subinterval and a common slope for each of the larger intervals. In this way, two tables of sizes 2^(a + b), for the initial value, and 2^(k – b), for the slope based on a bits and the point within the subinterval specified by k – a – b bits, are required in lieu of a single table of size 2^k. p. 404 [011002b] At the beginning of the last paragraph, change "Our second example" to "Our third example". p. 408 [010927e<4] The first line on the page (widow line) should be moved to the previous page. p. 409 [030425b] Add the following reference: [DasS95] Das Sarma, D. and D.W. Matula, “Faithful Bipartite ROM Reciprocal Tables,” Proc. 12th Symp. Computer Arithmetic, Bath, UK, 1995, pp. 17-28. p. 409 [011001a] Add the following reference: [Whit89] White, S.A., "Application of Distributed Arithmetic to Digital Signal Processing: A Tutorial Review," IEEE Acoustics, Speech, and Signal Processing, Vol. 6, pp. 4-19, July 1989. p. 418 [051031] In the caption of Fig. 25.4, change "Earl" to "Earle". p. 421 [030421k<4] At the end of the first paragraph in Section 25.5, cite: [Erce84], [Erce88] p. 422 [030425d<3] In the upper right corner of Fig. 25.7, just above the rightmost horizontal line segment, insert a square-root symbol (Ö). p. 424 [011114<4] In Fig. 25.11, bottom left corner, p should be italicized. p. 428 [030425e<3] Bad page break; move last line to next page. p. 429 [030421m<4] Add the reference: [Erce84] Ercegovac, M.D., “On-Line Arithmetic: An Overview,” Real-Time Signal Processing VII, SPIE Vol. 495, pp. 86-92, 1984. p. 429 [001206v] The following reference contains a good discussion of factors that limit the speedup achievable through pipelining. It is also a good source of ideas for problems.
[Dube90] Dubey, P.K. and M.J.
Flynn, "Optimal Pipelining," J.
Parallel and Distributed Computing, Vol. 8, pp. 10-19, 1990. p. 442 [030425m<4] At the end of the last paragraph, add the following two sentences: For general or tutorial material on low-power design, see [Kuro99], [Beni01], [Soud02]. Power consumption issues in general-purpose and high-performance microprocessors are treated in [Mudg01], [Gonz96]. p. 446 [030425f<4] Add the following references: [Beni01] Benini, L., G. De Micheli, and E. Macii, “Designing Low-Power Circuits: Practical Recipes,” IEEE Circuits and Systems, Vol. 1, No. 1, pp. 6-25, First Quarter 2001. [Gonz96] Gonzalez, R., and M. Horowitz, “Energy Dissipation in General-Purpose Microprocessors,” IEEE J. Solid-State Circuits, pp. 1277-1284, 1996. [Kuro99] Kuroda, T., and T. Sakurai, “Low Power CMOS VLSI Design,” Chap. 24 in Digital Signal Processing for Multimedia Systems, ed. by K.K. Parhi and T. Nishitani, Marcel Dekker, 1999, pp. 693-739. [Mudg01] Mudge, T., “Power: A First-Class Architectural Design Constraint,” IEEE Computer, Vol. 34, No. 4, pp. 52-58, April 2001. [Soud02] Soudris, D., C. Piguet, and C. Goutis (eds.), Designing CMOS Circuits for Low Power, Kluwer, 2002. p. 448 [010924b<4] On line 2, change "short-circit" to "short-circuit". p. 459 [030425g<4] At the end of the last paragraph of Section 27.5, add: For a review of algorithm-based fault tolerance methods, see [Vija97]. p. 463 [030425h<4] Add the following reference: [Vija97] Vijay, M. and R. Mittal, “Algorithm-Based Fault Tolerance: A Review,” Microprocessors and Microsystems, Vol. 21, pp. 151-161, 1997. p. 469 [030425j] On line 9 from bottom, right after [Jull94], cite the additional reference [Gass99]. p. 472 [001211d<4] In line 16, "86-bit floating-point format" should be "80-bit floating-point format (sign, 15-bit exponent field, 64-bit significand)". p. 473 [001211e<4] In Fig. 28.5, the three instances of "86" on connecting arrows should be "80". p. 474 [030421q<4] On line 9, at the end of the sentence "... all the required points" cite [Frie99]. p. 476 [001206x] Problem 28.9: The following reference contains a good description of TI’s C62x integer and C67x floating-point DSP chips which use VLIW RISC-type architectures and conditional instruction execution to achieve 1600 MIPS with 8 functional units. Each of two multi-ported register files allow 10 reads and 6 writes. [Sesh98] Seshan, N., “High VelociTI Processing”, IEEE Signal Processing, Vol. 15, No. 2, pp. 86-101, 117, March 1998. p. 476 [001206y] Problem 28.12: The following reference compares DEC Alpha 21164 (RISC) and Intel Pentium Pro or P6 (CISC) processors. The two are comparable in die area (approx. 300 mm^2) and technology. At 300 MHz, Alpha’s clock rate is twice that of P6. It outperforms P6 slightly on integer, and by a factor of about 2 on floating-point-intensive, computations.
[Bhan97]
Bhandarkar, D., “RISC versus CISC: A Tale of Two Chips,” Computer
Architecture News, Vol. 25, No. 1, pp. 1-12, March 1997. p. 477 [030421r<4] Add the reference:
[Frie99] Friedman, E.G.,
"Clock Distribution in Synchronous Systems," in Wiley Encyclopedia of Electrical and Electronics Engineering, Vol.
3, pp. 474-497, 1999. p. 478 [030425k] Add the following reference: [Gass99] Gass, W.K. and D.H. Bartley, “Programmable DSPs,” Chap. 9 in Digital Signal Processing for Multimedia Systems, ed. by K.K. Parhi and T. Nishitani, Marcel Dekker, 1999, pp. 225-244.
Return to: Top of this page || Go up to: B. Parhami's teaching and textbooks or his home page
|
|