Current Projects
Federated Learning
 |
In many large-scale machine learning (ML) applications, data is acquired and processed at the edge nodes of the network such as mobile devices, users’ devices, and IoT sensors. Federated Learning is a novel paradigm for privacy-preserving ML that aims to train a statistical model at the edge nodes by keeping the data local. While federated learning is a promising framework, there are several challenges that remain to be resolved and our group works on including communication bottleneck, provable privacy guarantees, heterogeneous system and data settings, and robustness to adversarial attacks. |
Robust Machine Learning
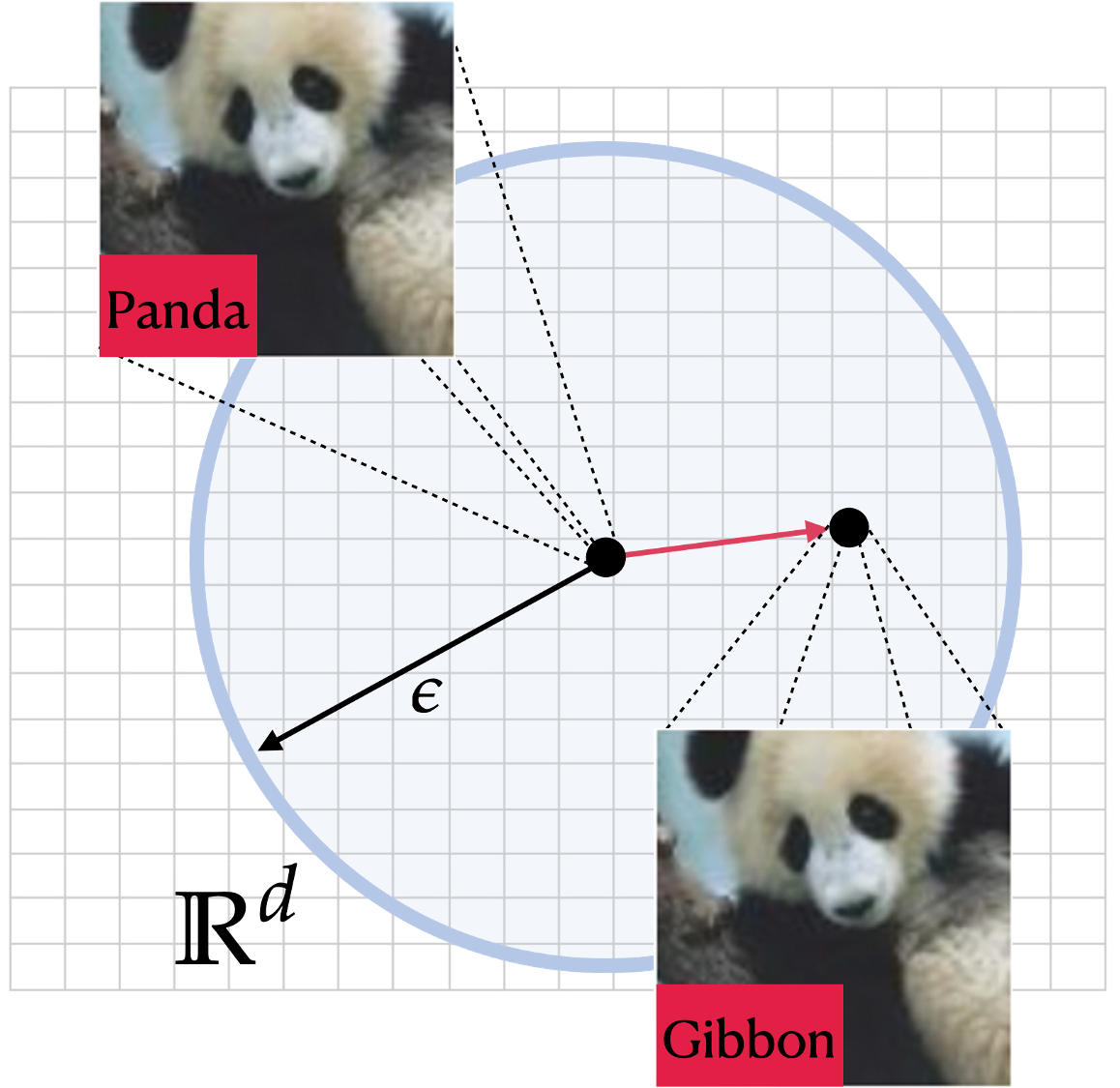 |
Adversarial attacks to machine learning models in the form of a small perturbation added to the input have been shown to be effective in causing classification errors. Formally, the adversary aims to perturb the data in a small lp- neighborhood so that the perturbed data is close to the original data (e.g., imperceptible perturbation in the case of an image) and misclassification occurs. While there have been a variety of attacks and defenses proposed in the literature which mostly focus on l2- or l∞-bounded perturbations, our group has recently focused on the fundamental limits of the adversarial ML problem with stylized mathematical models, and in particular investigated sparse attacks. We aim to characterize the optimal robust classifier and the corresponding robust error performance. |
Reinforcement and Imitation Learning
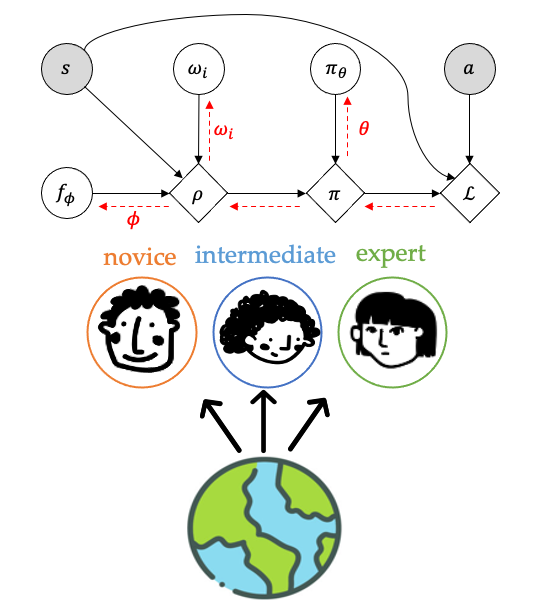 |
Reinforcement learning provides a powerful and general framework for tasks such as autonomous vehicles, assistive robots, or conversation agents, by optimizing behavior with respect to user-specified reward functions. However, online interaction with the environment can be costly or even unsafe. Instead, one can mitigate these issues by viewing the problem through the lens of offline learning, where the learner either has access to demonstrations of the task along with the corresponding reward values as in offline reinforcement learning, or only has access to expert demonstrations without any reward information as in imitation learning. Many existing imitation learning datasets are collected from multiple demonstrators, each with different expertise at different parts of the environment. Yet, standard imitation learning algorithms typically treat all demonstrators as homogeneous, regardless of their expertise, absorbing the weaknesses of any suboptimal demonstrators. In our group, we have worked on the use of unsupervised learning over demonstrator expertise and demonstrated that it can improve standard imitation learning frameworks. By optimizing a joint model over a learned policy and expertise levels of the demonstrators, our model is able to learn from optimal behavior while filtering out the suboptimal behavior of each demonstrator. |
Fairness in Machine Learning
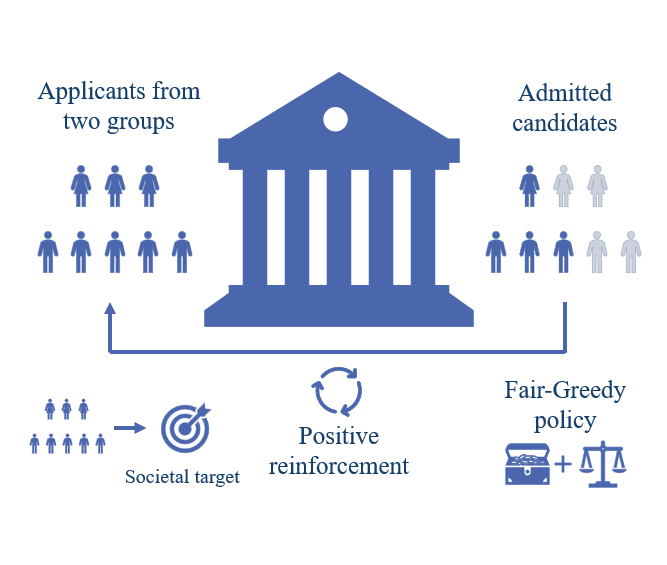 |
Machine learning models are being increasingly applied in making critical decisions that affect humans, such as recidivism prediction, mortgage lending, and recommendation systems. While the algorithms offer increased efficiency, speed, and scalability, they could introduce bias leading to the decisions being unfair towards certain groups of the population. In our group, we propose a framework for sequential decision-making aimed at dynamically influencing long-term societal fairness, illustrated via the problem of selecting applicants from a pool consisting of different groups, e.g. two groups one of which is under-represented. We consider a dynamic model for the composition of the applicant pool, and aim to characterize a fairness criteria and an optimal policy that can balance accuracy and fairness in the long run. |
Intelligent Transportation Networks with Mixed Autonomy
|
|
The advent of autonomous vehicles promises to transform transportation and mobility. While the most dramatic changes likely remain decades away, semiautonomous capabilities such as adaptive cruise control are already available. These technologies will coexist and interact with traditional, manually driven vehicles into the foreseeable future. As a result, transportation infrastructure is entering a stage of mixed use whereby vehicles are capable of varying levels of autonomy. In this project, we develop models and algorithms for controlling mixed traffic flow where some fraction of vehicles are equipped with varying levels of autonomy and the remaining are manually driven. In particular, we develop models of link and network capacity for mixed traffic, and utilize these models to develop algorithms for management and control of mixed traffic. |
Past Projects
Codes for Speeding Up Large-Scale Distributed Machine Learning
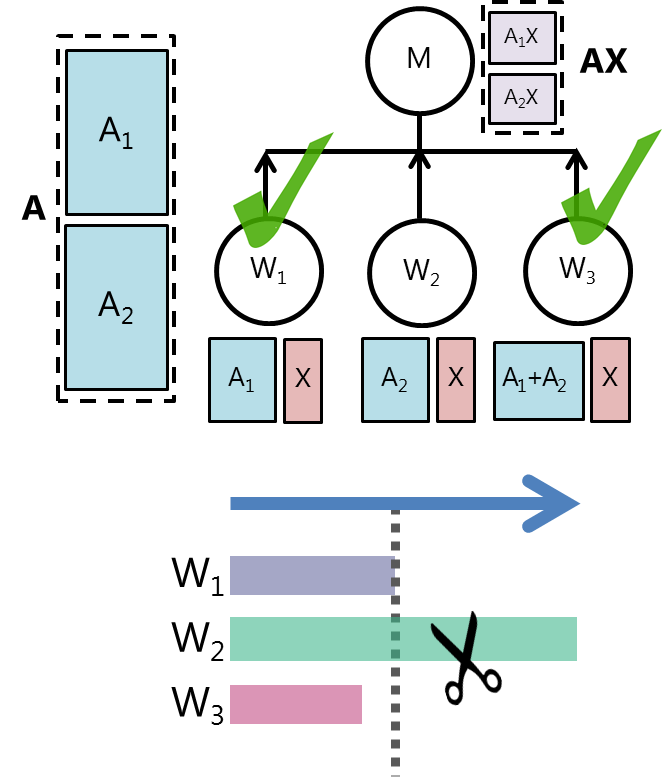 |
Distributed machine learning algorithms that dominate the use of modern large-scale computing platforms face several types of randomness, uncertainty and system noise. These include straggler nodes, system failures, maintenance outages, and communication bottlenecks. In this project, we view distributed machine learning algorithms through a coding-theoretic lens, and design coded algorithms that provide robustness against this system noise. Our goal is to understand fundamental trade-offs in distributed computation between latency of computation, redundancy in computation, communication bottlenecks and storage capacities. |
Robust Scheduling for Large-Scale Networks
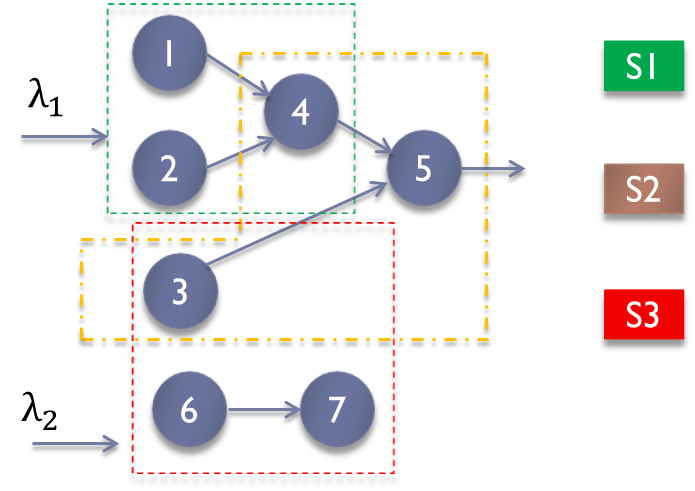 |
Networked infrastructures such as data centers and transportation systems are rapidly growing in size and demand. These large-scale networks are often characterized by unknown and time-varying parameters that makes the design of optimal control strategies more challenging. In this project, we develop mathematical models for various networks that span diverse application areas from job scheduling in data centers to healthcare systems. The focus of this project is to design simple, distributed, and robust scheduling algorithms that maximize the throughput of the systemin the presence of uncertainty in network parameters. |
Sparse Recovery of High-Dimensional Signals
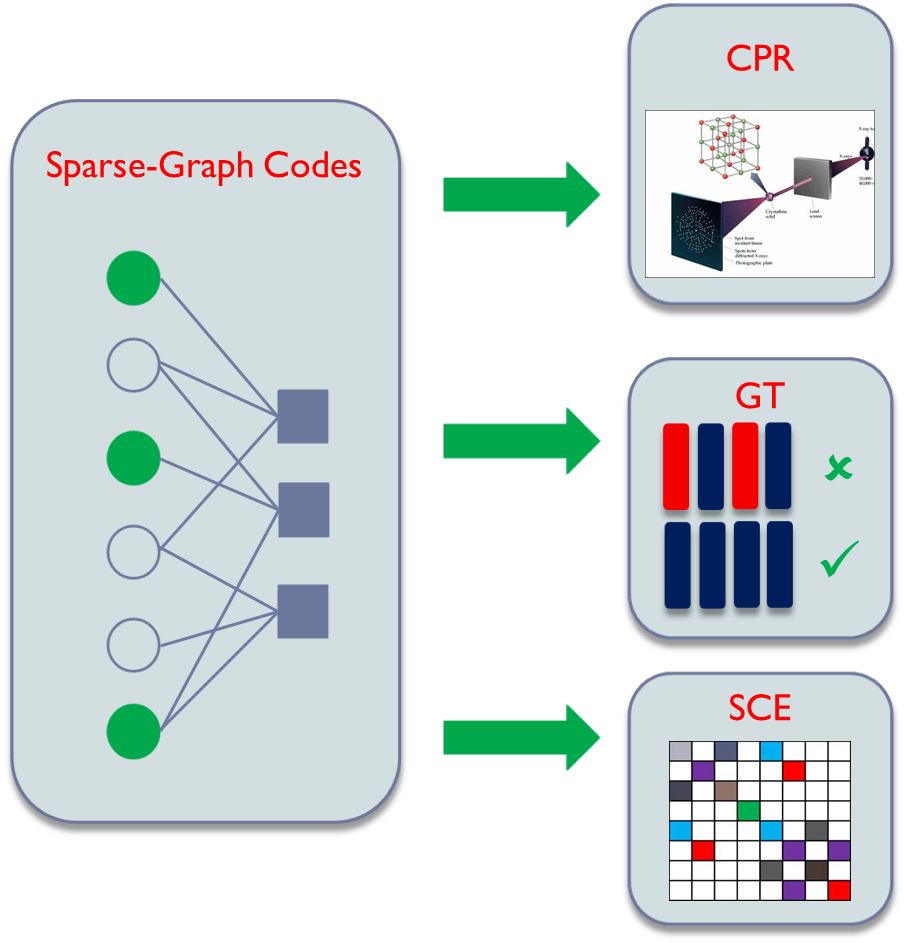 |
The past several years have seen a new approach to the recovery of high-dimensional signals, where a few sketches of the signal retain sufficient information for an approximate sparse recovery. This approach has found numerous applications in the areas of signal processing, imaging, data stream computing, etc. In this project, our focus is to exploit tools from modern coding theory to design fast and efficient reconstruction algorithms for a variety of problems including compressed sensing, compressive phase retrieval, group testing, and mixed linear regression. |