
Menu:
Behrooz Parhami's ECE 254B Course Page for Winter 2019
Adv. Computer Architecture: Parallel Processing
Page last updated on 2019 March 21
Enrollment code: 13938
Prerequisite: ECE 254A (can be waived, but ECE 154B is required)
Class meetings: MW 10:00-11:30, Phelps 1431
Instructor: Professor Behrooz Parhami
Open office hours: M 12:00-2:00, W 1:00-2:00, HFH 5155
Course announcements: Listed in reverse chronological order
Course calendar: Schedule of lectures, homework, exams, research
Homework assignments: Eight assignments, worth a total of 30%
Exams: Closed-book midterm, 30%; Closed-book final, 40%
Research paper: No research paper for winter 2019
Research paper guidlines: Brief guide to format and contents (N/A)
Poster presentation tips: Brief guide to format and structure (N/A)
Policy on academic integrity: Please read very carefully
Grade statistics: Range, mean, etc. for homework and exam grades
References: Textbook and other sources (Textbook's web page)
Lecture slides: Available on the textbook's web page
Miscellaneous information: Motivation, catalog entry, history
Course Announcements
 2019/03/21: The winter 2019 offering of ECE 254B is officially over and grades have been reported to the Registrar. Have a nice spring break and hope to see some of you in my graduate course ECE 252B (Computer Arithmetic) during spring 2019.
2019/03/21: The winter 2019 offering of ECE 254B is officially over and grades have been reported to the Registrar. Have a nice spring break and hope to see some of you in my graduate course ECE 252B (Computer Arithmetic) during spring 2019.
2019/03/09: Given the cancellation of my office hour on W 3/13, I will hold extra office hours on R 3/14, 1:00-3:00 PM. I will make solutions to HW8 available at that time, so you can submit your last homework by 1:00 PM on R 3/14.
2019/03/04: HW8 has been posted to the homework area below. HW7 is due on W 03/06.
2019/02/24: HW7 has been posted to the homework area below. HW6 is due on W 02/27.
2019/02/18: HW6 has been posted to the homework area below. Grade stats for HW4, HW5, and midterm exam are available.
2019/02/10: I am cancelling the ECE 254B lecture and office hour on W 3/13, in order to attend the day-long CS Summit at UCen's Corwin Pavilion. The highlight of that day is a keynote lecture by Lise Getoor (CS Professor, UCSC), entitled "Responsible Data Science." In lieu of the cancelled lecture, I highly recommend optional attendance at an ECE Department Distinguished Lecture by Dr. John Paul Strachen (HP Labs, Palo Alto), entitled "A New Era for Exploring Power Efficient Hardware Accelerators: Devices, Architectures, and Lab Demonstrations," which is highly relevant to our course (Thursday, February 28, 2019, 10:00 AM, ESB 1001).
2019/02/03: HW5 has been posted to the homework area below. Grade stats for HW3 are available.
2019/01/28: HW4 has been posted to the homework area below. Grade stats for HW2 are available.
2019/01/21: HW3 has been posted to the homework area below. Grade stats for HW1 are available.
2019/01/14: HW2 has been posted to the homework area below.
2019/01/07: HW1 has been posted to the homework area below. Course enrollment now stands at 16.
2019/01/05: Updated slides for Part I (Chapters 1-2) have been posted to the textbook's Web page. HW1 will be posted in a couple of days.
2018/12/15: Welcome to the ECE 254B web page for winter 2019. As of today, 14 students have signed up for the course. I will use the lecture slides from 2016 with minimal changes. Where more than cosmetic improvements are made to the slides, you will be informed through these announcements, so that you can download the updated presentations. Looking forward to seeing you all in the first class session on Monday 2019/01/07.
Course Calendar

Course lectures and homework assignments have been scheduled as follows. This schedule will be strictly observed. In particular, no extension is possible for homework due dates; please start work on the assignments early. Each lecture covers topics in 1-2 chapters of the textbook. Chapter numbers are provided in parentheses, after day & date. PowerPoint and PDF files of the lecture slides can be found on the textbook's web page.
Day & Date (book chapters) Lecture topic [Homework posted/due] {Special notes}
M 01/07 (1) Introduction to parallel processing
W 01/09 (2) A taste of parallel algorithms [HW1 posted; chs. 1-2]
M 01/14 (3-4) Complexity and parallel computation models
W 01/16 (5) The PRAM shared-memory model and basic algorithms [HW1 due] [HW2 posted; chs. 3-4]
M 01/21 No lecture: Martin Luther King Holiday
W 01/23 (6A) More shared-memory algorithms [HW2 due] [HW3 posted, chs. 5-6A]
M 01/28 (6B-6C) Shared memory implementations and abstractions
W 01/30 (7) Sorting and selection networks [HW3 due] [HW4 posted; chs. 6B-7]
M 02/04 (8A) Search acceleration circuits
W 02/06 (8B-8C) Other circuit-level examples [HW4 due] [HW5 posted; chs. 8A-8C]
M 02/11 (1-7) Closed-book midterm exam {10:00-11:45 AM}
W 02/13 (9) Sorting on a 2D mesh or torus architectures [HW5 due]
M 02/18 No lecture: President's Day Holiday
W 02/20 (10) Routing on a 2D mesh or torus architectures [HW6 posted; chs. 9-10]
M 02/25 (11-12) Other mesh/torus concepts
W 02/27 (13) Hypercubes and their algorithms [HW6 due] [HW7 posted; chs. 11-13]
M 03/04 (14) Sorting and routing on hypercubes
W 03/06 (15-16) Other interconnection architectures [HW7 due] [HW8 posted; chs. 14-16]
M 03/11 (17) Emulation and task scheduling and input/output {Instructor/course evaluation surveys}
W 03/13 (18-19) Input/output and reliability considerations [HW8 due]
M 03/18 (8A-19) Closed-book final exam {8:30-11:00 AM}
T 03/26 {Course grades due by midnight}
Homework Assignments
 - Turn in solutions as a single PDF file attached to an e-mail sent by the due date/time.
- Turn in solutions as a single PDF file attached to an e-mail sent by the due date/time.
- Because solutions will be handed out on the due date, no extension can be granted.
- Include your name, course name, and assignment number at the top of the first page.
- If homework is handwritten and scanned, make sure that the PDF is clean and legible.
- Although some cooperation is permitted, direct copying will have severe consequences.
Homework 1: Introduction and overview (chs. 1-2, due W 2019/01/16, 10:00 AM)
Do the following problems from the textbook: 1.9, 1.24 (defined below), 2.3, 2.6
1.24 Warehouse-scale parallel computers
Read Chapter 1 of [Barr19] and present in one PowerPoint slide the definition of warehouse-scale computers and the reasons we should care about them. Use no more than 6 bullet points on your slide.
[Barr19] Barroso, L. A., U. Holzle, and P. Ranganathan, The Data Center as a Computer: Designing Warehouse-Scale Machines, Morgan & Claypool, 3rd ed., 2019.
If you can't access the 2019 3rd edition of the book, use the 2013 2nd edition, which is available on-line.
Homework 2: Complexity and models (chs. 3-4, due W 2019/01/23, 10:00 AM)
Do the following problems from the textbook: 3.1, 3.7ab, 4.11ab, 4.15 (defined below)
4.15 SIMD vs. SPMD parallel processing
Consider the SIMD and SPMD models of parallel computation. Write a one-page brief that answers the following questions.
a. Under what conditions is SIMD preferable to SPMD, and vice versa?
b. Is it feasible to design a parallel computer that can switch between SIMD and SPMD, so as to take advantage of the strengths of each mode? (Hint: [Augu87])
[Augu87] Auguin, M., F. Boeri, J. P. Dalban, and A. Vincent-Carrefour, "Experience Using a SIMD/SPMD Multiprocessor Architecture," Microprocessing and Microprogramming, Vol. 21, Nos. 1-5, pp. 171-177, August 1987.
Homework 3: PRAM and basics of shared memory (chs. 5-6A, due W 2019/01/30, 10:00 AM)
Do the following problems from the textbook: 5.4, 5.9, 6.3, 6.17 (defined below)
6.17 Plurality voting on the PRAM
Devise an efficient PRAM algorithm for "plurality voting." There are p processors and a vector x[1..p] of data values. The algorithm should compute a pair of results y and w such that the value y = x[j] appears w times in x and no other value has more appearances. For example, x = 5 7 4 5 4 should yield y = 5 or y = 4 with w = 2, since both 5 and 4 appear twice in x, whereas 7 appears only once.
a. Describe your algorithm in high-level terms, using known subalgorithms if needed.
b. Analyze the worst-case running time of the algorithm.
c. How much simpler can the algorithm become if standard "majority voting" is desired? Assume that a majority always exists and that only the single result y is to be computed.
Homework 4: Shared memory and sorting networks (chs. 6B-7, due W 2019/02/06, 10:00 AM)
Do the following problems from the textbook: 6.25 (defined below), 7.4, 7.16ab, 16.13
6.25 Performance implications of memory consistency
Read the paper [Ghar91] and present in one PowerPoint slide why different memory consistency models have varying performance overheads/penalties. Your PowerPoint slide should be sparse (6 or fewer bullet points), focusing on key notions in brief, headline-like statements, rather than complete sentences or paragraphs.
[Ghar91] Gharachorloo, K., A. Gupta, J. Hennessy, "Performance Evaluation of Memory Consistency Models for Shared-Memory Multiprocessors," ACM SIGARCH Computer Architecture News, Vol. 19, No. 2, pp. 245-257, April 1991.
Homework 5: More circuit-level examples (chs. 8A-8C, due W 2019/02/13, 10:00 AM)
Do the following problems from the textbook: 8.4a, 8.7, 8.15ab, 8.24 (defined below)
8.24 Accelerator architectures
Read the paper [Hwu18] and present in one PowerPoint slide the notion of accelerator architectures, how they have evolved over the years, and why they are in broad use today. [Please follow the previous guidelines on what makes a good slide.]
[Hwu18] Hwu, W.-M. and S. Patel, "Accelerator Architectures—A Ten-Year Retrospective," IEEE Micro, Vol. 38, No. 6, pp. 56-62, November-December 2018.
Homework 6: Basics of mesh and torus (chs. 9-10, due W 2019/02/27, 10:00 AM)
Do the following problems from the textbook: 9.6, 9.19 (defined below), 10.5, 10.11
9.19 Analysis of shearsort
On a p-processor 2D mesh with one dimension equal to x (x < √p), is shearsort faster when x is the number of rows or the number of columns? Fully justify your answer.
Homework 7: Mesh variations and hypercube (chs. 11-13, due W 2019/03/06, 10:00 AM)
Do the following problems from the textbook: 11.2, 11.8, 12.4ab, 13.21 (defined below)
13.21 Embedding parameters
The three examples in Fig. 13.2 suggest that dilation, congestion, and load factor are orthogonal parameters in the sense that knowing two of them does not provide much, if any, information about the third. Reinforce this conclusion by constructing, when possible, additional examples for which dilation, congestion, and load factor are (respectively):
a. 1, 1, 2
b. 1, 2, 1
c. 2, 1, 1
d. 2, 1, 2
e. 2, 2, 2
Homework 8: Hypercube and other architectures (chs. 14-16, due W 2019/03/13, 10:00 AM)
Do the following problems from the textbook: 14.8, 14.13, 15.13, 16.18 (defined below)
16.18 Node degree and network diameter
In a degree-d undirected graph, there are at most d nodes that are at hop distance 1 from a given node.
a. Prove that there are at most d^k nodes that are at hop distance k or less from a given node.
b. Use the result of part a to derive an upper bound for the network diameter D and compare this bound to Moore's bound for undirected graphs given in Section 16.1.
Sample Exams and Study Guides

The following sample exams using problems from the textbook are meant to indicate the types and levels of problems, rather than the coverage (which is outlined in the course calendar). Students are responsible for all sections and topics, in the textbook, lecture slides, and class handouts, that are not explicitly excluded in the study guide that follows the sample exams, even if the material was not covered in class lectures.
Sample Midterm Exam (105 minutes)
Textbook problems 2.3, 3.5, 5.5 (with i + s corrected to j + s), 7.6a, and 8.4ac; note that problem statements might change a bit for a closed-book exam.
Midterm Exam Study Guide
The following sections are excluded from Chapters 1-7 of the textbook to be covered in the midterm exam, including the six new chapters named 6A-C (expanding on Chpater 6) and 8A-C (expanding on Chapter 8):
3.5, 4.5, 4.6, 6A.6, 6B.3, 6B.5, 6C.3, 6C.4, 6C.5, 6C.6, 7.6
Sample Final Exam (150 minutes)
Textbook problems 1.10, 6.14, 9.5, 10.5, 13.5a, 14.10, 16.1; note that problem statements might change a bit for a closed-book exam.
Final Exam Study Guide
The following sections are excluded from Chapters 1-16 of the textbook to be covered in the final exam: All midterm exclusions, plus 8A.5, 8A.6, 8B.2, 8B.5, 8B.6, 9.6, 12.6, 13.5, 15.5, 16.5, 16.6
Research Paper and Presentation

[Not for winter 2019] Our research focus this quarter will be on the topical area of big data, as defined in class and the reading/research assignments for the first three course homeworks. We will study the intersection of big data with high-performance computing, that is, how the meteoric spread of big-data applications affects the field of parallel/distributed computing and how research in our field can help solve the challenges brought about by big data.
The "4 Vs" of big data are nicely illustrated in the following IBM infographic. The fourth "V," equated in the image with "veracity," having to do with correctness and accuracy of data, is sometimes replaced by "value" (see the ssecond homework assignment), the data's importance or worth to an enterprise or application. Alternatively, one might view the big-data domain as being defined by "5 Vs."
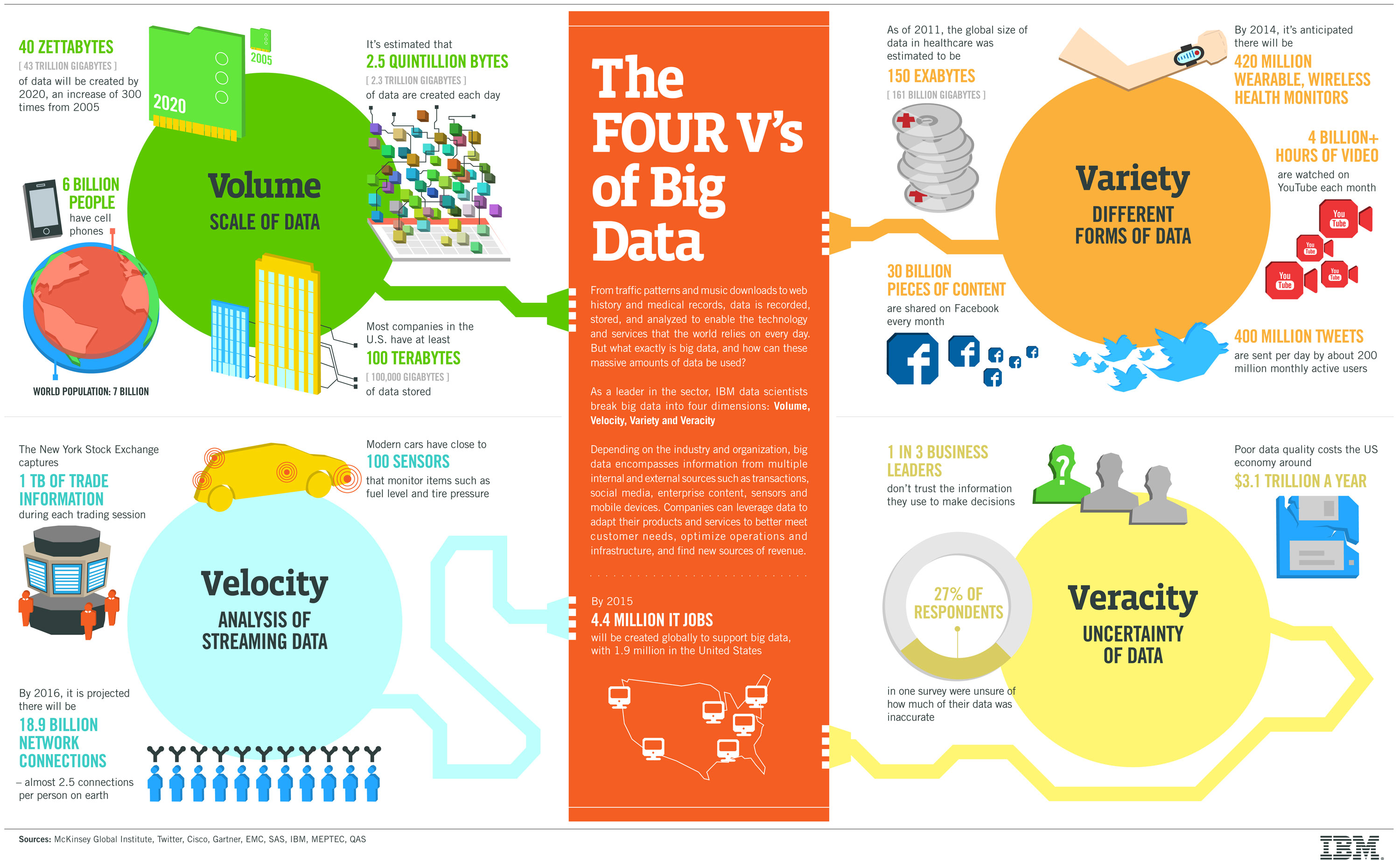
Here is a list of research paper titles. I am posting the list, even though some of the info is incomplete, in order to give you a head start on choosing a topic. In topic selection, you can either propose a topic of your choosing, which I will review and help you refine into something that would be manageable and acceptable for a term paper, or you can give me your first to third choices among the topics that follow. I will then assign a topic to you by February 12, based on your preferences and those of your classmates. Sample references follow the titles to help define the topics and serve as starting pointa for your study.
1. Hybrid Disk Drives for Big-Data Storage Needs (Assigned to: Chang Lu)
[Wu09] X. Wu and A. L. Narasimha Reddy, "Managing Storage Space in a Flash and Disk Hybrid Storage System," Proc. IEEE Int'l Symp. Modeling, Analysis, and Simulation of Computer and Telecommunication Systems, 2009, pp. 1-4.
Search terms: Flash disk cache
2. GPU-Based Parallel Architectures for Big Data (Assigned to: Barath K. Ramaswami)
[Liu13] Z. Liu, B. Jiang, and J. Heer, "imMens: Real-Time Visual Querying of Big Data," Computer Graphics Forum, Vol. 32, No. 3, 2013, pp. 421-430.
Search terms: GPU-based supercomputing
3. Network Coding for Fast Exchange of Big Data (Assigned to: John Zhou)
[Dima10] A. G. Dimakis, P. B. Godfrey, Y. Wu, M. J. Wainwright, and K. Ramchandran, "Network Coding for Distributed Storage Systems," IEEE Trans. Information Theory, Vol. 56, No. 9, 2010, pp. 4539-4551.
Search terms:
4. Big-Data Allocation and Load-Balancing Methods (Assigned to: Haowen Zhang)
[Wang14] K. Wang, X. Zhou, T. Li, D. Zhao, M. Lang, and I. Raicu, "Optimizing Load Balancing and Data-Locality with Data-Aware Scheduling," Proc. IEEE Int'l Conf. Big Data, 2014, pp. 119-128.
Search terms:
5. Low-Redundancy Methods for Big-Data Protection (Assigned to: Yunxi Li)
[Amja12] T. Amjad, M. Sher, and A. Daud, "A Survey of Dynamic Replication Strategies for Improving Data Availability in Data Grids," Future Generation Computer Systems, Vol. 28, No. 2, 2012, pp. 337-349.
Search terms:
6. RAID in the Era of Cloud-Based Big-Data Storage (Assigned to: Haorui Jiang)
[Gu14] M. Gu, X. Li, and Y. Cao, "Optical Storage Arrays: A Perspective for Future Big Data Storage," Light: Science & Applications, Vol. 3, No. 5, 2014.
Search terms:
7. Structural Representations for Big-Data Storage (Assigned to: No one)
[Sand14] A. Sandryhaila and J. M. F. Moura, "Big Data Analysis with Signal Processing on Graphs: Representation and Processing of Massive Data Sets with Irregular Structure," IEEE Signal Processing, Vol. 31, No. 5, 2014, pp. 80-90.
Search terms:
8. Meeting Reliability Requirements of Big Data (Assigned to: No one)
[Sath13] M. Sathiamoorthy, M. Asteris, D. Papailiopoulos, A. G. Dimakis, R. Vadali, S. Chen, and D. Borthakur, "XORing Elephants: Novel Erasure Codes for Big Data," Proc. Symp. VLDB, Vol. 6, No. 5, 2013, pp. 325-336.
Search terms: Reliable distributed systems; Data integrity
9. Search and Query Optimizations for Big Data (Assigned to: Rongjian Li)
[Du92] W. Du, R. Krishnamurthy, and M.-C. Shan. "Query Optimization in a Heterogeneous DBMS," Proc. Symp. VLDB, 1992, Vol. 92, pp. 277-291.
Search terms:
10. The MapReduce Paradigm for Big-Data Parallelism (Assigned to: Zhicheng Zhang)
[Dean10] J. Dean and S. Ghemawat, "MapReduce: A Flexible Data Processing Tool," Communications of the ACM, Vol. 53, No. 1, 2010, pp. 72-77.
Search terms: Data-parallel computing; Divide-and-conquer paradigm
11. Hadoop's Distributed File System for Big Data (Assigned to: Yulin Ou)
[Shva10] K. Shvachko, H. Kuang, S. Radia, and R. Chansler, "The Hadoop Distributed File System," Proc. 26th IEEE Symp. Mass Storage Systems and Technologies, 2010, pp. 1-10.
Search terms: Hadoop; Distributed file systems; Distributed databases
12. Big-Data Longevity and Compatibility Challenges (Assigned to: Brian Young)
[Garf04] T. Garfinkel, B. Pfaff, J. Chow, and M. Rosenblum, "Data Lifetime Is a Systems Problem," Proc. 11th ACM SIGOPS European Workshop, 2004, p. 10.
Search terms: Data preservation; Long-term data archiving
13. Advances in Intelligent Systems with Big Data (Assigned to: Pooja V. Kadam)
[OLea13] D. E. O'Leary, "Artificial Intelligence and Big Data," IEEE Intelligent Systems, Vol. 28, No. 2, 2013, pp. 96-99.
Search terms: Data-driven AI; Large training data-sets
14. FPGA-Based Accelerators for Big-Data Computing (Assigned to: Gokul P. Nallasami)
[Wang15] C. Wang, X. Li, and X. Zhou, "SODA: Software Defined FPGA Based Accelerators for Big Data," Proc. Design Automation & Test Europe Conf., 2015, pp. 884-887.
Search terms: Hardware accelerators; Application-specific coprocessors
15. Big-Data Aspects of Distributed Sensor Networks (Assigned to: Zhaoren Zeng)
[Taka14] D. Takaishi, H. Nishiyama, N. Kato, and R. Miura, "Toward Energy Efficient Big Data Gathering in Densely Distributed Sensor Networks," IEEE Trans. Emerging Topics in Computing, Vol. 2, No. 3, pp. 388-397, 2014.
Search terms: Ad-hoc networks; Data storage in sensor networks
16. Big-Data Challenges of Maps and Auto-Navigation (Assigned to: Jiaheng Tang)
[Shek12] S. Shekhar, V. Gunturi, M. R. Evans, and K. Yang, "Spatial Big-Data Challenges Intersecting Mobility and Cloud Computing." Proc. 11th ACM Int'l Workshop Data Engineering for Wireless and Mobile Access, 2012, pp. 1-6.
Search terms: Geographic information systems; GPS navigation
17. Shared-Memory Models for Big-Data Applications (Assigned to: Yang Zhao)
[Bell18] C. G. Bell and I. Nassi, "Revisiting Scalable Coherent Shared Memory," IEEE Computer, Vol. 51, No. 1, pp. 40-49, January 2018.
Search terms: Memory consistency; Distributed shared memory; Directory-based coherence
18. Edge Computing for Big Data (Assigned to: Leilai Shao)
[Shar17] S. K. Sharma and X. Wang, "Live Data Analytics With Collaborative Edge and Cloud Processing in Wireless IoT Networks," IEEE Access, Vol. 5, pp. 4621-4635, 2017.
Poster Presentation Tips
[Not for winter 2019] Here are some guidelines for preparing your research poster. The idea of the poster is to present your research results and conclusions thus far, get oral feedback during the session from the instructor and your peers, and to provide the instructor with something to comment on before your final report is due. Please send a PDF copy of the poster via e-mail by midnight on the poster presentation day.
Posters prepared for conferences must be colorful and eye-catching, as they are typically competing with dozens of other posters for the attendees' attention. Here is an example of a conference poster. Such posters are often mounted on a colored cardboard base, even if the pages themselves are standard PowerPoint slides. In our case, you should aim for a "plain" poster (loose sheets, to be taped to the wall in our classroom) that conveys your message in a simple and direct way. Eight to 10 pages, each resembling a PowerPoint slide, would be an appropriate goal. You can organize the pages into 2 x 4 (2 columns, 4 rows), 2 x 5, or 3 x 3 array on the wall. The top two of these might contain the project title, your name, course name and number, and a very short (50-word) abstract. The final two can perhaps contain your conclusions and directions for further work (including work that does not appear in the poster, but will be included in your research report). The rest will contain brief description of ideas, with emphasis on diagrams, graphs, tables, and the like, rather than text which is very difficult to absorb for a visitor in a very limited time span.
{kind=link}
Grade Statistics
 All grades listed below are in [0.0, 4.3] (F to A+), unless otherwise noted
All grades listed below are in [0.0, 4.3] (F to A+), unless otherwise noted
HW1 grades: Range = [D, A], Mean = 3.5, Median = A–
HW2 grades: Range = [B, A], Mean = 3.6, Median = B+/A–
HW3 grades: Range = [B, A], Mean = 3.3, Median = B+
HW4 grades: Range = [B–, A], Mean = 3.2, Median = B+
HW5 grades: Range = [B–, A], Mean = 3.4, Median = B+
HW6 grades: Range = [C, A], Mean = 3.4, Median = A–
HW7 grades: Range = [B–, A–], Mean = 3.5, Median = A–
HW8 grades: Range = [B–, A], Mean = 3.4, Median = B+
Overall homework grades (percent): Range = [70, 96], Mean = 85, Median = 87
Midterm exam grades (percent): Range = [53, 94], Mean = 68, Median = 67
Final exam grades (percent): Range = [41, 85], Mean = 69, Median = 72
Course letter grades: Range = [B, A], Mean = 3.6, Median = A–
References

Required text: B. Parhami, Introduction to Parallel Processing: Algorithms and Architectures, Plenum Press, 1999. Make sure that you visit the textbook's web page which contains an errata. Lecture slides are also available there.
Optional recommended book: T. Rauber and G. Runger, Parallel Programming for Multicore and Cluster Systems, 2nd ed., Springer, 2013. Because ECE 254B's focus is on architecture and its interplay with algorithms, this book constitutes helpful supplementary reading.
On-line: N. Matloff, Programming Parallel Machines: GPU, Multicore, Clusters, & More. [Link]
Research resources:
The follolwing journals contain a wealth of information on new developments in parallel processing: IEEE Trans. Parallel and Distributed Systems, IEEE Trans. Computers, J. Parallel & Distributed Computing, Parallel Computing, Parallel Processing Letters, ACM Trans. Parallel Computing. Also, see IEEE Computer and IEEE Concurrency (the latter ceased publication in late 2000) for broad introductory articles.
The following are the main conferences of the field: Int'l Symp. Computer Architecture (ISCA, since 1973), Int'l Conf. Parallel Processing (ICPP, since 1972), Int'l Parallel & Distributed Processing Symp. (IPDPS, formed in 1998 by merging IPPS/SPDP, which were held since 1987/1989), and ACM Symp. Parallel Algorithms and Architectures (SPAA, since 1988).
UCSB library's electronic journals, collections, and other resources
Miscellaneous Information
Motivation: The ultimate efficiency in parallel systems is to achieve a computation speedup factor of p with p processors. Although often this ideal cannot be achieved, some speedup is generally possible by using multiple processors in a concurrent (parallel or distributed) system. The actual speed gain depends on the system's architecture and the algorithm run on it. This course focuses on the interplay of architectural and algorithmic speedup techniques. More specifically, the problem of algorithm design for "general-purpose" parallel systems and its "converse," the incorporation of architectural features to help improve algorithm efficiency and, in the extreme, the design of algorithm-based special-purpose parallel architectures, are dealt with. The foregoing notions will be covered in sufficient detail to allow extensions and applications in a variety of contexts, from network processors, through desktop computers, game boxes, Web server farms, multiterabyte storage systems, and mainframes, to high-end supercomputers.
Catalog entry: 254B. Advanced Computer Architecture: Parallel Processing(4) PARHAMI. Prerequisites: ECE 254A. Lecture, 4 hours. The nature of concurrent computations. Idealized models of parallel systems. Practical realization of concurrency. Interconnection networks. Building-block parallel algorithms. Algorithm design, optimality, and efficiency. Mapping and scheduling of computations. Example multiprocessors and multicomputers.
History: The graduate course ECE 254B was created by Dr. Parhami, shortly after he joined UCSB in 1988. It was first taught in spring 1989 as ECE 594L, Special Topics in Computer Architecture: Parallel and Distributed Computations. A year later, it was converted to ECE 251, a regular graduate course. In 1991, Dr. Parhami led an effort to restructure and update UCSB's graduate course offerings in the area of computer architecture. The result was the creation of the three-course sequence ECE 254A/B/C to replace ECE 250 (Adv. Computer Architecture) and ECE 251. The three new courses were designed to cover high-performance uniprocessing, parallel computing, and distributed computer systems, respectively. In 1999, based on a decade of experience in teaching ECE 254B, Dr. Parhami published the textbook Introduction to Parallel Processing: Algorithms and Architectures (Website).
Offering of ECE 254B in winter 2018 (Link)
Offering of ECE 254B in winter 2017 (Link)
Offering of ECE 254B in winter 2016 (PDF file)
Offering of ECE 254B in winter 2014 (PDF file)
Offering of ECE 254B in winter 2013 (PDF file
Offering of ECE 254B in fall 2010 (PDF file)
Offering of ECE 254B in fall 2008 (PDF file)
Offerings of ECE 254B from 2000 to 2006 (PDF file)