
Menu:
Behrooz Parhami's Textook on Dependable Computing

Page last updated on 2023 October 01
B. Parhami, Dependable Computing: A Multilevel Approach, Publisher and date TBD.
(ISBN TBD, xxx + xx pp., xxx figures, xxx problems)
The author is looking for a publisher, while also considering the prospects of publishing this textbook as a free on-line resource. Please stay tuned for further developments. An instructor's solutions manual is in the works. For lecture slides and other teaching aids, see below.
Downloadable Text Parts (in PDF format)
Presentations, Lecture Slides (in PowerPoint & PDF formats)
Dedication (to Professors R. A. Short and A. A. Avizienis)
Preface (with contents-at-a-glance and general references)
Complete Table of Contents
Instructor's Solutions Manual (Preface, and how to order)
List of Errors
Additions and Internet Resources
Author's Graduate Course on Dependable Computing
Note: The cover design shown is a placeholder. It will be replaced by the actual cover image once the design becomes available. The two elements in this image convey the ideas that computer system dependability is a weakest-link phenomenon and that modularization & redundancy can be employed, in a manner not unlike the practice in structural engineering, to prevent failures or to limit their impact.
Downloadable Text Parts
The following PDF files for the seven parts of the textbook are available for downloading (file sizes up to 5 MB).
![]() Part I — Introduction: Dependable Systems (pdf, last updated on 2023/10/01)
Part I — Introduction: Dependable Systems (pdf, last updated on 2023/10/01)
Part II — Defects: Physical Imperfections (pdf, last updated on 2020/10/11)
Part III — Faults: Logical Deviations (pdf, last updated on 2020/10/23)
Part IV — Errors: Informational Distortions (pdf, last updated on 2020/11/01)
Part V — Malfunctions: Architectural Anomalies (pdf, last updated on 2020/11/12)
Part VI — Degradations: Behavioral Lapses (pdf, last posted on 2020/11/19)
Part VII — Failures: Computational Breaches (pdf, last updated on 2020/11/25)
Presentations, Lecture Slides
The following PowerPoint and PDF presentations for the seven parts of the textbook are available for downloading (file sizes up to 4 MB).
 Part I — Introduction: Dependable Systems (ppt, pdf, last updated 2023/10/01)
Part I — Introduction: Dependable Systems (ppt, pdf, last updated 2023/10/01)
Part II — Defects: Physical Imperfections (ppt, pdf, last updated 2020/10/12)
Part III — Faults: Logical Deviations (ppt, pdf, last updated 2020/10/23)
Part IV — Errors: Informational Distortions (ppt, pdf, last updated 2020/11/01)
Part V — Malfunctions: Architectural Anomalies (ppt, pdf, last updated 2020/11/12)
Part VI — Degradations: Behavioral Lapses (ppt, pdf, last updated 2020/11/19)
Part VII — Failures: Computational Breaches (ppt, pdf, last updated 2020/11/25)
Dedication
 To my academic mentors of long ago:
To my academic mentors of long ago:
Professor Robert Allen Short (1927-2003),
who taught me digital systems theory
and encouraged me to publish my first research paper on
stochastic automata and reliable sequential machines,
and

Professor Algirdas Antanas Avizienis (1932- )
who provided me with a comprehensive overview
of the dependable computing discipline
and oversaw my maturation as a researcher.
Preface
"The skill of writing is to create a context in which other people can think."
(Edwin Schlossberg)
"When a complex system succeeds, that success masks its proximity to failure. ... Thus, the failure of the Titanic contributed much more to the design of safe ocean liners than would have her success. That is the paradox of engineering and design."
(Henry Petroski, Success through Failure: The Paradox of Design)
[The multilevel model on the right of the following table is shown to emphasize its influence on the structure of this book; the model is explained in Chapter 1, Section 1.4.]
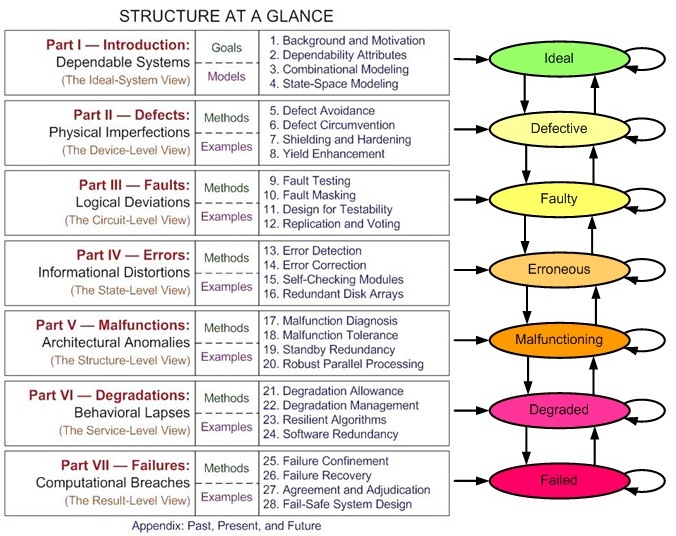
The context of Dependable Computing
Accounts of computer system errors, failures, and other mishaps range from humorous to horrifying. On the lighter side, we have data entry or computation errors that lead to an electric company sending a bill for hundreds of thousands of dollars to a small residential customer. Such errors cause a chuckle or two as they are discussed at the dinner table and are usually corrected to everyone's satisfaction, leaving no permanent damage (though in a few early occurrences of this type, some customers suffered from their power being disconnected due to nonpayment of the erroneous bill). At the other extreme, there are dire consequences such as an airliner with hundreds of passengers on board crashing, two high-speed commuter trains colliding, a nuclear reactor taken to the brink of meltdown, or financial markets in a large industrial country collapsing. Causes of such annoying or catastrophic behavior range from design deficiencies, interaction of several rare or unforeseen events, operator errors, external disturbances, or malicious actions.
In nearly all engineering and industrial disciplines, quality control is an integral part of the design and manufacturing processes. There are also standards and guidelines that make at least certain aspects of quality assurance more or less routine. This is far from being the case in computer engineering, particularly with regard to software products. True, we do offer dependable computing courses to our students, but in doing so, we create an undesirable separation between design and dependability concerns. A structural engineer does not learn about bridge-building in one course and about ensuring that bridges do not collapse in another. A toaster or steam-iron manufacturer does not ship its products with a warning label that there is no guarantee that the device will prepare toast or remove wrinkles from clothing and that the manufacturer will not be liable for any harm resulting from their use.
The field of dependable (aka fault-tolerant) computing was born in the late 1960s, because longevity, safety, and robustness requirements of space and military applications could not be met through conventional design. Space applications presented the need for long-life systems, with either no possibility of on-board maintenance and repair (unmanned missions) or with stringent reliability requirements in harsh, and relatively unpredictable environments (manned missions). Military applications required extreme robustness in the face of punishing operational conditions, partial system wipeout, or targeted attacks by a sophisticated adversary. Early researchers of the field were thus predominantly supported by aerospace and defense organizations.
Of course, designing computer systems that were robust, self-reconfiguring, and ultimately self-repairing was only one part of the problem. There was also a need to quantify various aspects of system dependability via detailed and faithful models that would allow the designers of such systems to gain the confidence and trust of the user community. A failure probability of one-in-a-billion, say, was simply too low to allow experimental assessment and validation, as such experiments would have required the construction and testing of many millions of copies of the target system in order to allow general conclusions of reasonable certainty to be drawn. Thus, research-and-development teams in dependable computing pursued analytical and simulation models to help with the evaluation process. Extending and fine-tuning of such models is one of the main activity threads in the field.
As the field matured, application areas broadened beyond aerospace and military systems and they now include a wide array of systems, from automotive computers to large redundant disk arrays. In fact, many of the methods discussed in this book are routinely utilized even in contexts that do not satisfy the traditional definitions of high-risk or safety-critical systems, although the most elaborate techniques continue to be developed for systems whose failure would endanger human lives. Systems in the latter category include:
- Advanced infrastructure and transportation systems, such as high-speed trains
- Process control in hazardous environments, such as nuclear power plants
- Patient monitoring and emergency health-care procedures, as in surgical robots
Such advanced techniques then trickle down and eventually find their way into run-of-the-mill computer systems, such as traditional desktop and laptop computers.
The goals and structure of this book
The field of dependable computing has matured to the point that a dozen or so texts and reference books have been published. Some of these books that cover dependable computing in general (as opposed to special aspects or ad-hoc/unconventional methods) are listed at the end of this preface. Each of these books possesses unique strengths and has contributed to the formation and fruition of the field. The current text, Dependable Computing: A Multilevel Approach, exposes the reader to the basic concpets of dependable computing in sufficient detail to enable their use in many hardware/software contexts. Covered methods include monitoring, redundancy, error detection/correction, self-test, self-check, self-repair, adjudication, and fail-soft operation. The book is an outgrowth of lecture notes that the author has developed and refined over many years. Here are the most important features of this text in comparison to the listed books:
a. Division of material into lecture-size chapters: In my approach to teaching, a lecture is a more or less self-contained module with links to past lectures and pointers to what will transpire in future. Each lecture must have a theme or title and must proceed from motivation, to details, to conclusion. In designing the text, I have strived to divide the material into chapters, each of which is suitable for one lecture (1-2 hours). A short lecture can cover the first few subsections while a longer lecture can deal with variations, peripheral ideas, or more advanced material near the end of the chapter. To make the structure hierarchical, as opposed to flat or linear, lectures are grouped into seven parts, each composed of four lectures and covering one level in our multilevel model (see the figure above).
b. Emphasis on both the underlying theory and actual system designs: The ability to cope with complexity requires both a deep knowledge of the theoretical underpinnings of dependable computing and examples of designs that help us understand the theory. Such designs also provide building blocks for synthesis as well as reference points for cost-performance comparisons. This viewpoint is reflected, for example, in the detailed coverage of error-coding techniques that later lead to a better understanding of various of self-checking design methods (Part IV). Another example can be found in Chapter 17 where the rigorous discussion of malfunction diagnosis allows a more systematic treatment of reconfiguration and self-repair.
c. Linking dependable computing to other subfields of computing: Dependable computing is nourished by, and in turn feeds other subfields of computer systems and technology. Examples of such links abound. Parallel and distributed computing is a case in point, given that such systems contain multiple resources of each kind and thus offer the possibility of sharing spare subsystems for greater efficiency. In fact, one can even find links to topics outside traditional science and engineering disciplines. For example, designers of redundant systems with replication and voting can learn a great deal from the treatment of voting systems by mathematicians and social scientists. Such links are pointed out and pursued throughout the text.
d. Wide coverage of important topics: The current text covers virtually all important algorithmic and hardware design topics in dependable computing, thus providing a balanced and complete view of the field. Coverage of testable design, voting algorithms, software redundancy, and fail-safe systems do not all appear in other textbooks.
e. Unified and consistent notation/terminology throughout the text: Every effort is made to use consistent notation/terminology throughout the text. For example, R always stands for reliability and s for the number of spare units. While other authors have done this in the basic parts of their texts, there is a tendency to cover more advanced research topics by simply borrowing the notation and terminology from the reference source. Such an approach has the advantage of making the transition between reading the text and the original reference source easier, but it is utterly confusing to the majority of the students who rely on the text and do not consult the original references except, perhaps, to write a research paper.
Summary of topics
The seven parts of this book, each composed of four chapters, have been written with the following goals:
Part I sets the stage, gives a taste of what is to come, and provides a detailed perspective on the assessment of dependability in computing systems and the modeling tools needed for this purpose.
Part II deals with impairments to dependability at the physical (device) level, how they may lead to system vulnerability and low integrated-circuit yield, and what countermeasures are available for dealing with them.
Part III deals with impairments to dependability at the logical (circuit) level, how the resulting faults can affect system behavior, and how redundancy methods can be used to deal with them.
Part IV covers information-level impairments that lead to data-path and control errors, methods for detecting/correcting such errors, and ways of preventing such errors from propagating and causing problems at even higher levels of abstraction.
Part V deals with everything that can go wrong at the architectural level, that is, at the level of interactions between subsystems, be they parts of a single computer or nodes in a widely distributed system.
Part VI covers service-level impairments that may cause a system not to be able to perform the required tasks, even though it has not totally failed in an absolute sense.
Part VII deals with breaches at the computation-result or outcome level, where the success or failure of a computing system is ultimately judged and the costs of aberrant results or actions must be borne.
Pointers on how to use the book
For classroom use, the topics in each chapter of this text can be covered in a lecture spanning 1-2 hours. In his own teaching, the author has used the chapters primarily for 1.5-hour lectures, twice a week, in a 10-week quarter, omitting or combining some chapters to fit the material into 18-20 lectures. But the modular structure of the text lends itself to other lecture formats, self-study, or review of the field by practitioners. In the latter two cases, the readers can view each chapter as a study unit (for one week, say) rather than as a lecture. Ideally, all topics in each chapter should be covered before moving to the next chapter. However, if fewer lecture hours are available, then some of the subsections located at the end of chapters can be omitted or introduced only in terms of motivations and key results.
Problems of varying complexities, from straightforward numerical examples or exercises to more demanding studies or mini-projects, have been supplied for each chapter. These problems form an integral part of the book and have not been added as afterthoughts to make the book more attractive for use as a text. A total of xxx problems are included (xx-xx per chapter). Assuming that two lectures are given per week, either weekly or biweekly homework can be assigned, with each assignment having the specific coverage of the respective half-part (two chapters) or full part (four chapters) as its "title".
An instructor's solutions manual is planned. The author's detailed syllabus for the course ECE 257A at UCSB is available at:
http://www.ece.ucsb.edu/~parhami/ece_257a.htm
References to classical papers in dependable computing key design ideas, and important state-of-the-art research contributions are listed at the end of each chapter. These references provide good starting points for doing in-depth studies or for preparing term papers/projects.
New ideas in the field of dependable computing appear in papers presented at an annual technical gathering, the Dependable Systems and Networks (DSN) conference, jointly sponsored by the Institute of Electrical and Electronics Engineers (IEEE) and the International Federation for Information Processing (IFIP). DSN, which was formed by merging meetings sponsored separately by IEEE and IFIP, is composed of the following two main forums, plus a number of workshops and tutorials:
– The Dependable Computing and Communication Symposium (DCCS)
– The Performance and Dependability Symposium (PDS)
Other conferences include Pacific Rim International Symposium on Dependable Computing [PRDC], Symposium on Reliable Distributed Systems [SRDS], and International Conference on Computer Design [ICCD]. The field's most pertinent archival journals are IEEE Transactions on Dependable and Secure Computing [TDSC], IEEE Transactions on Reliability [TRel], IEEE Transactions on Computers [TCom], and The Computer Journal [ComJ].
Acknowledgments
The current text, Dependable Computing: A Multilevel Approach, is an outgrowth of lecture notes that the author has used for the graduate course "ECE 257A: Fault-Tolerant Computing" at the University of California, Santa Barbara, and, in rudimentary forms, at several other institutions prior to 1988. The text has benefited greatly from keen observations, curiosity, and encouragement of my many students in these courses. A sincere thanks to all of them!
General references
The list that follows contains references of two types: (1) books that have greatly influenced the current text and (2) general reference sources for in-depth study or research. Books and other information sources that are relevant to specific chapters are listed in the end-of-chapter reference lists.
[Ande81] Anderson, T., and P. A. Lee, Fault Tolerance: Principles and Practice, Prentice Hall, 1981.
[Ande85] Anderson, T. A. (ed.), Resilient Computing Systems, Collins, 1985. Also: Wiley, 1986.
[ComJ] The Computer Journal, published monthly by the British Computer Society.
[Comp] IEEE Computer, magazine published by the IEEE Computer Society. Has published several special issues on dependable computing: Vol. 17, No. 6, August 1984; Vol. 23, No. 5, July 1990.
[CSur] ACM Computing Surveys, journal published by the Association for Computing Machinery.
[Diab05] Diab, H. B., and A. Y. Zomaya (eds.), Dependable Computing Systems: Paradigms, Performance Issues, and Applications, Wiley, 2005.
[DSN] Proc. IEEE/IFIP Int'l Conf. Dependable Systems and Networks, Conference formed by merging earlier series of meetings, the oldest of which (FTCS) dated back to 1971. URL: http://www.dsn.org
[Dunn02] Dunn, W. R., Practical Design of Safetry-Critical Computer Systems, Reliability Press, 2002.
[Geff02] Geffroy, J.-C., and G. Motet, Design of Dependable Computing Systems, Kluwer, 2002.
[Gray85] Gray, J., "Why Do Computers Stop and What Can Be Done About It?" Technical Report TR85.7, Tandem Corp., 1985.
[ICCD] Proc. IEEE Int'l Conf. Computer Design, sponsored annually by the IEEE Computer Society since 1983.
[IFIP] Web site of the International Federation for Information Processing Working Group WG 10.4 on Dependable Computing. http://www.dependability.org/wg10.4
[Jalo] Jalote, P., Fault Tolerance in Distributed Systems, Prentice Hall, 1994.
[John89] Johnson, B. W., Design and Analysis of Fault-Tolerant Digital Systems, Addison-Wesley, 1989.
[Kore07] Koren, I., and C. M. Krishna, Fault-Tolerant Systems, Morgan Kaufmann, 2007.
[Lala01] Lala, P. K., Self-Checking and Fault-Tolerant Digital Design, Morgan Kaufmann, 2001.
[Levi94] Levi, S.-T., and A. K. Agrawala, Fault-Tolerant System Design, McGraw-Hill. 1994.
[Negr89] Negrini, R., M. G. Sami, and R. Stefanelli, Fault Tolerance Through Reconfiguration in VLSI and WSI Arrays, MIT Press, 1989.
[Nels87] Nelson, V. P., and B. D. Carroll (eds.), Tutorial: Fault-Tolerant Computing, IEEE Computer Society Press, 1987.
[Prad86] Pradhan, D. K. (ed.), Fault-Tolerant Computing: Theory and Techniques, 2 Vols., Prentice Hall, 1986.
[Prad96] Pradhan, D. K. (ed.), Fault-Tolerant Computer System Design, Prentice Hall, 1996.
[PRDC] Proc. IEEE Pacific Rim Int'l Symp. Dependable Computing, sponsored by IEEE Computer Society and held every 1-2 years since 1989.
[Shoo02] Shooman, M. L., Reliability of Computer Systems and Networks, Wiley, 2002.
[Siew82] Siewiorek, D. P., and R.S. Swarz, The Theory and Practice of Reliable System Design, Digital Press, 1982.
[Siew92] Siewiorek, D. P., and R. S. Swarz, Reliable Computer Systems: Design and Evaluation, Digital Press, 2nd Edition, 1992. Also: A. K. Peters, 1998.
[SRDS] Proc. IEEE Symp. Reliable Distributed Systems, sponsored annually by IEEE Computer Society.
[TCom] IEEE Trans. Computers, journal published by the IEEE Computer Society. Has publlished a number of sepecial issues on dependable computing: Vol. 41, No. 2, February 1992; Vol. 47, No. 4, April 1998; Vol. 51, No. 2, February 2002.
[TDSC] IEEE Trans. Dependable and Secure Computing, journals published by the IEEE Computer Society.
[TRel] IEEE Trans. Reliability, quarterly journal published by IEEE Reliability Society.
Book Reviews
None at this time.
Complete Table of Contents
Note: Each chapter ends with sections entitled "Problems" and "References and Further Readings."
Part I — Introduction: Dependable Systems
1 Background and Motivation ~
1.1 The need for dependability ~
1.2 A motivating case study ~
1.3 Impairments to dependability ~
1.4 A multilevel model ~
1.5 Examples and analogies ~
1.6 Dependable computer systems
2 Dependability Attributes ~
2.1 Aspects of dependability ~
2.2 Reliability and MTTF ~
2.3 Availability, MTTR, and MTBF ~
2.4 Performability and MCBF ~
2.5 Integrity and safety ~
2.6 Privacy and security
3 Combinational Modeling ~
3.1 Modeling by case analysis ~
3.2 Series and parallel systems ~
3.3 Classes of k-out-of-n systems ~
3.4 Reliability block diagrams ~
3.5 Reliability graphs ~
3.6 The fault-tree method
4 State-Space Modeling ~
4.1 Markov chains and models ~
4.2 Modeling nonrepairable systems ~
4.3 Modeling repairable systems ~
4.4 Modeling fail-soft systems ~
4.5 Solving Markov models ~
4.6 Dependability modeling in practice
Part II — Defects: Physical Imperfections
5 Defect avoidance ~
5.1 Types and causes of defects ~
5.2 Yield and its associated costs ~
5.3 Defect modeling ~
5.4 The bathtub curve ~
5.5 Burn-in and stress testing ~
5.6 Active Defect Prevention
6 Defect Circumvention ~
6.1 Detection of defects ~
6.2 Redundancy and reconfiguration ~
6.3 Defective memory arrays ~
6.4 Defects in logic and FPGAs ~
6.5 Defective 1D and 2D arrays ~
6.6 Other circumvention methods
7 Shielding and Hardening ~
7.1 Interference and cross-talk ~
7.2 Shielding via enclosures ~
7.3 The radiation problem ~
7.4 Radiation hardening ~
7.5 Vibrations, shocks, and spills ~
7.6 Current practice and trends
8 Yield Enhancement ~
8.1 Yield models ~
8.2 Redundancy for yield enhancement ~
8.3 Floorplanning and routing ~
8.4 Improving memory yield ~
8.5 Regular processor arrays ~
8.6 Impact of process variations
Part III — Faults: Logical Deviations
9 Fault Testing ~
9.1 Overview and fault models ~
9.2 Path sensitization and D-algorithm ~
9.3 Boolean difference methods ~
9.4 The complexity of fault testing ~
9.5 Testing of units with memory ~
9.6 Off-line vs. concurrent testing
10 Fault Masking ~
10.1 Fault avoidance vs. masking ~
10.2 Interwoven redundant logic ~
10.3 Static redundancy with replication ~
10.4 Dynamic and hybrid redundancy ~
10.5 Time redundancy ~
10.6 Variations and complications
11 Design for Testability ~
11.1 The importance of testability ~
11.2 Testability modeling ~
11.3 Testpoint insertion ~
11.4 Sequential scan techniques ~
11.5 Built-in self-test ~
11.6 Testing of analog and hybrid circuits
12 Replication and Voting ~
12.1 Hardware redundancy overview ~
12.2 Replication in space ~
12.3 Replication in time ~
12.4 Mixed space/time replication ~
12.5 Switching and voting units ~
12.6 Variations and design issues
Part IV — Errors: Informational Distortions
13 Error Detection ~
13.1 Basics of error detection ~
13.2 Checksum codes ~
13.3 Weight-based and Berger codes ~
13.4 Cyclic codes ~
13.5 Arithmetic error-detecting codes ~
13.6 Other error-detecting codes
14 Error Correction ~
14.1 Basics of error correction ~
14.2 Hamming codes ~
14.3 Linear codes ~
14.4 Reed-Solomon and BCH codes ~
14.5 Arithmetic error-correcting codes ~
14.6 Other error-correcting codes
15 Self-Checking Modules ~
15.1 Checking of function units ~
15.2 Error signals and their combining ~
15.3 Totally self-checking design ~
15.4 Self-checking checkers ~
15.5 Self-checking state machines ~
15.6 Practical self-checking design
16 Redundant Disk Arrays ~
16.1 Disk drives and disk arrays ~
16.2 Disk mirroring and striping ~
16.3 Data encoding schemes ~
16.4 RAID and its levels ~
16.5 Disk array performance ~
16.6 Disk array reliability modeling
Part V — Malfunctions: Architectural Anomalies
17 Malfunction Diagnosis ~
17.1 Self-diagnosability in subsystems ~
17.2 Malfunction diagnosis models ~
17.3 One-step diagnosability ~
17.4 Sequential diagnosability ~
17.5 Diagnostic accuracy and resolution ~
17.6 Other topics in diagnosis
18 Malfunction Tolerance ~
18.1 System-level reconfiguration ~
18.2 Isolating a malfunctioning element ~
18.3 Data and state recovery ~
18.4 Regular arrays of modules ~
18.5 Low-redundancy sparing ~
18.6 Malfunction-tolerant scheduling
19 Standby Redundancy ~
19.1 Malfunction detection ~
19.2 Cold and hot spare units ~
19.3 Conditioning of spares ~
19.4 Switching over to spares ~
19.5 Self-repairing systems ~
19.6 Modeling of self-repair
20 Robust Parallel Processing ~
20.1 A graph-theoretic framework ~
20.2 Connectivity and parallel paths ~
20.3 Dilated internode distances ~
20.4 Malfunction-tolerant routing ~
20.5 Embeddings and emulations ~
20.6 Robust multistage networks
Part VI — Degradations: Bahavioral Lapses
21 Degradation Allowance ~
21.1 Graceful degradation ~
21.2 Diagnosis, isolation, and repair ~
21.3 Stable storage ~
21.4 Process and data recovery ~
21.5 Checkpointing and rollback ~
21.6 Optimal checkpoint insertion
22 Degradation Management ~
22.1 Data distribution methods ~
22.2 Multiphase commit protocols ~
22.3 Dependable communication ~
22.4 Dependable collaboration ~
22.5 Remapping and load balancing ~
22.6 Modeling of degradable systems
23 Resilient Algorithms ~
23.1 COTS-based paradigms ~
23.2 Robust data structures ~
23.3 Data Diversity and Fusion ~
23.4 Self-checking algorithms ~
23.5 Self-adapting algorithms ~
23.6 Other algorithmic methods
24 Software Redundancy ~
24.1 Software dependability ~
24.2 Software malfunction models ~
24.3 Software verification and validation ~
24.4 N-version programming ~
24.5 The recovery block method ~
24.6 Hybrid software redundancy
Part VII — Failures: Computational Breaches
25 Failure Confinement ~
25.1 From failure to disaster ~
25.2 Failure awareness ~
25.3 Failure and risk assessment ~
25.4 Limiting the damage ~
25.5 Failure avoidance strategies ~
25.6 Ethical considerations
26 Failure Recovery ~
26.1 Planning for recovery ~
26.2 Interfaces and the human link ~
26.3 Fail-over strategies ~
26.4 Backup systems and processes ~
26.5 Blame assessment and liability ~
26.6 Learning from failures
27 Agreement and Adjudication ~
27.1 Voting and data fusion ~
27.2 Weighted voting ~
27.3 Voting with agreement sets ~
27.4 Variations in voting ~
27.5 Distributed agreement ~
27.6 Byzantine resiliency
28 Fail-Safe System Design ~
28.1 Fail-safe system concepts ~
28.2 Principles of safety engineering ~
28.3 Fail-safe specifications ~
28.4 Fail-safe combinational circuits ~
28.5 Fail-safe state machines ~
28.6 System- and user-level safety
Appendix: Past, Present, and Future ~ A.1 Historical perspective ~ A.2 Long-life systems ~ A.3 Safety-critical systems ~ A.4 High-availability systems ~ A.5 Commercial and personal systems ~ A.6 Trends, outlook, and resources
Preface to the Instructor's Solutions Manual
This manual, which will be provided gratis by the publisher to insructors who adopt Dependable Computing: A Multilevel Approach, contains solutions to selected end-of-chapter problems. Please refrain from posting any of these solutions to course Web sites, so that the textbook does not lose its value for other instructors.
A variety of other information and teaching resources, as well as an errata for both the textbook and this manual, are available via the author's companion Web site at:
http://www.ece.ucsb.edu/~parhami/text_dep_comp.htm
The author would appreciate the reporting of any error in the textbook or in this manual, suggestions for additional problems, alternate solutions to solved problems, solutions to other problems, and sharing of teaching experiences. Please e-mail your comments to "parhami at ece dot ucsb dot edu" or send them by regular mail to the author's postal address:
Dept. Electrical & Computer Engineering
University of California
Santa Barbara, CA 93106-9560, USA
Contributions will be acknowledged to the extent possible.
List of Errors

None at this time.
Additions and Internet Resources

None at this time.