
Menu:
Behrooz Parhami's Textbook on Computer Architecture

Page last updated on 2019 July 02
B. Parhami, Computer Architecture: From Microprocessors to Supercomputers, Oxford Univ. Press, New York, 2005. (ISBN 0-19-515455-X, 556+xix pages, 300 figures, 491 end-of-chapter problems)
Available for purchase from Oxford University Press and various college or on-line bookstores. Instructor's solutions manual is provided gratis by Oxford Univ. Press to instructors who adopt the textbook.
Roadmap for Using This Book (PDF file)
Presentations, Lecture Slides (in PowerPoint & PDF formats)
Preface (with contents-at-a-glance and list of general references)
Complete Table of Contents
Instructor's Solutions Manual (Preface, and how to order)
List of Errors (for the text and its solutions manual)
Additions to the Text, and Internet Resources
Translated Editions (Spanish)
Author's Undergraduate Course on Computer Architecture
Disclaimer and Credits: This book uses the MIPS instruction-set architecture to provide concrete examples for machine instructions and hardware structures required for their execution. As a prominent example of the class of reduced instruction-set architectures (RISC), MIPS has been found quite suitable for use in various educational settings. References to simplified RISC instruction sets under the designations MiniMIPS and MicroMIPS, introduced in Chapters 5 and 13, respectively, have no relations with specific architectures offered by MIPS Technologies, Inc. These simplifications form proper subsets of the well-documented MIPS instruction set and have not been otherwise modified. Reference is also made to SPIM, a software simulator for the MIPS instruction set, which is provided free of charge to everyone, courtesy of Dr. James R. Larus.
Presentations, Lecture Slides
The following PowerPoint and PDF presentations for the seven parts of the textbook are available for downloading.
 Part 1: Background and Motivation (ppt, pdf, last updated 2014/10/02)
Part 1: Background and Motivation (ppt, pdf, last updated 2014/10/02)
Part 2: Instruction-Set Architecture (ppt, pdf, last updated 2014/10/15)
Part 3: The Arithmetic/Logic Unit (ppt, pdf, last updated 2014/10/28)
Part 4: Data Path and Control (ppt, pdf, last updated 2014/11/18)
Part 5: Memory System Design (ppt, pdf, last updated 2014/12/04)
Part 6: Input/Output and Interfacing (ppt, pdf, last updated 2011/02/11)
Part 7: Advanced Architectures (ppt, pdf, last updated 2011/02/23)
Preface
"... there is a tendency when you really begin to learn something about a thing not to want to write about it but rather to keep on learning about it ... unless you are very egotistical, which, of course, accounts for many books." Ernest Hemingway, Death in the Afternoon
The context of computer arhitecture
Computer architecture is an area of study dealing with digital computers at the interface between hardware and software. It is more hardware-oriented than "computer systems," an area typically covered in courses by the same name in computer science or engineering, and more concerned with software than the fields known as "computer design" and "computer organization." The subject matter, nevertheless, is quite fluid and varies greatly from one textbook or course to another in its orientation and coverage. This explains, in part, why there are so many different textbooks on computer architecture and why yet another textbook on the subject might serve a useful purpose.
Computer architecture encompasses a set of core ideas that are applicable to the design or understanding of virtually any computer, from the tiniest embedded microprocessors that control our appliances, cameras, and numerous other devices through personal, server, and mainframe machines to the most powerful supercomputers found only in (and affordable only by) large data centers or major scientific laboratories. It also branches into more advanced subfields, each with its own community of researchers, periodicals, symposia, and, of course, technical jargon. Computer designers must no doubt be familiar with the entire field to be able to use the range of available methods in designing fast, efficient, and robust systems. Less obvious is the fact that even simple computer users can benefit from a firm grasp of the core ideas and from an awareness of the more advanced concepts in computer architecture.
A common theme in computer architecture is coping with complexity. Much of this complexity arises from our desire to make everything as fast as possible. Some of the resulting techniques, such as predictive and speculative execution, are at odds with other goals of system design that include low cost, compactness, power economy, short time to market, and testability. It is the constant push and pull of such conflicting requirements that makes computer architecture a thriving and exciting field of study. Adding to the excitement are the opposing forces of innovation and compatibility with existing investments in skills, systems, and applications
Scope and Features
This textbook, an outgrowth of lecture notes that the author has developed and refined over many years, covers the core ideas of computer architecture in some depth and provides an overview of many advanced concepts that may be pursued in higher-level courses such as those on supercomputing, parallel processing, and distributed systems.
Six key features set this book apart from competing introductory textbooks on computer architecture:
a. Division of material into lecture-size chapters: In the author's approach to teaching, a lecture is a more or less self-contained module with links to past lectures and pointers to what will transpire in future. Each lecture, lasting one to two hours, has a theme or title and proceeds from motivation to details to conclusion.
b. A large number of meaningful problems: At least 16 problems have been provided at the end of each of the 28 chapters. These are well-thought-out problems, many of them class-tested, that clarify the chapter material, offer new viewing angles, link the chapter material to topics in other chapters, or introduce more advanced concepts.
c. Emphasis on both the underlying theory and actual designs: The ability to cope with complexity requires both a deep understanding of the theoretical underpinnings of computer architecture and examples of designs that help clarify the theory. Such designs also provide building blocks for synthesis and reference points for cost-performance comparisons.
d. Linking computer architecture to other subfields of computing: Computer architecture is nourished by, and in turn feeds, other subfields of computer system design. Such links, from the obvious (instruction-set architecture vis-a-vis compiler design) to the subtle (interplay of architecture with reliability and security), are explained throughout the book.
e. Broad coverage of important topics: The text covers virtually all the core topics in computer architecture, thus providing a balanced and complete view of the field. Examples of material not found in many other texts include detailed coverage of computer arithmetic (Chapters 9-12) and high-performance computing (Chapters 25-28).
f. Unified and consistent notation/terminology: Every effort is made to use consistent notation/terminology throughout the text. For example, r always stands for the number representation radix, k for word width, and c, for carry. Similarly, concepts and structures are consistently identified with unique, well-defined names.
Summary of topics
The seven parts of this book, each composed of four chapters, have been written with the following goals:
Part 1 sets the stage, provides context, reviews some of the prerequisite topics, and gives a taste of what is to come in the rest of the book. Included are two refresher-type chapters on digital circuits and components, a discussion of computer system types, an overview of digital computer technology, and a detailed perspective on computer system performance.
Part 2 lays out the user's interface to computer hardware, also known as the instruction-set architecture (ISA). For concreteness, the instruction set of MiniMIPS (a simplified, yet very realistic, machine for which open reference material and simulation tools exist) is described. Included is a chapter on variations in ISA (e.g., RISC vs CISC) and associated cost-performance trade-offs.
The next two parts cover the central processing unit (CPU). Part 3 describes the structure of arithmetic/logic units (ALUs) in some detail. Included are discussions of fixed- and floating-point number representations, design of high-speed adders, shift and logical operations, and hardware multipliers/dividers. Implementation aspects and pitfalls of floating-point arithmetic are also discussed.
Part 4 is devoted to the data path and control circuits comprising modern CPUs. Beginning with stages of instruction execution, the needed components and control mechanisms are derived. This material is followed by an exposition of control design strategies, use of a pipelined data path for performance enhancement, and various limitations of pipelining due to data and control dependencies.
Part 5 is concerned with the memory system. The technologies in use for primary and secondary memories are described, along with their strengths and limitations. It is shown how the use of cache memories effectively bridges the speed gap between CPU and main memory. Similarly, the use of virtual memory to provide the illusion of a vast main memory is explained.
Part 6 deals with input/output and interfacing topics. A discussion of I/O device technologies is followed by methods of I/O programming and the roles of buses and links (including standards) in I/O communication and interfacing. Elements of processes and context switching, for exception handling or multithreaded computation, are also covered.
Part 7 introduces advanced architectures. An overview of performance enhancement strategies, beyond simple pipelining, is presented, and examples of applications requiring higher performance are cited. The book concludes with design strategies and example architectures based on vector or array processing, multiprocessing, and multicomputing.
Pointers on how to use the book
For classroom use, the topics in each chapter of this text can be covered in a lecture of duration 1-2 hours. In his own teaching, the author has used the chapters primarily for 1.5-hour lectures, twice a week, in a 10-week quarter, omitting or combining some chapters to fit the material into the 18-20 lectures that are available. But the modular structure of the text lends itself to other lecture formats, self-study, or review of the field by practitioners. In the latter two cases, the readers can view each chapter as a study unit (for one week, say) rather than as a lecture. Ideally, all topics in each chapter should be covered before moving to the next chapter. However, if fewer lecture hours are available, then some of the subsections located at the end of chapters can be omitted or introduced only in terms of motivations and key results.
Problems of varying complexities, from straightforward numerical examples or exercises to more demanding studies or miniprojects, have been supplied for each chapter. These problems form an integral part of the book and have not been added as afterthoughts to make the book more attractive for use as a text. A total of 491 problems are included. Assuming that two lectures are given per week, either weekly or biweekly homework can be assigned, with each assignment having the specific coverage of the respective half-part (two chapters) or part (four chapters) as its "title."
An instructor's manual, with problem solutions, is available and can be requested by qualified instructors from Oxford University Press in New York (www.oup.com/us/highered). PowerPoint presentations, covering the seven parts, are available electronically through the author's Web page for the book at www.oup.com/us/PARHAMI. [From this OUP catalog page, follow the "Companion Website" link.] The book's Web page also includes a list of corrections and additional topics.
References to seminal papers in computer architecture, key design ideas, and important state-of-the-art research contributions are listed at the end of each chapter. These references provide good starting points for doing in-depth studies or for preparing term papers/projects. A large number of classical papers and important contributions in computer architecture have been reprinted in [Swar76], [Siew82], and [Sohi98]. New ideas in the field appear in papers presented at the annual International Symposium on Computer Architecture [ISCA]. Other technical meetings of interest include Symposium on High-Performance Computer Architecture [HPCA], International Parallel and Distributed Processing Symposium [IPDP], and International Conference on Parallel Processing [ICPP]. Relevant journals include IEEE Transactions on Computers [TrCo], IEEE Transactions on Parallel and Distributed Systems [TrPD], Journal of Parallel and Distributed Computing [JPDC], and Communications of the ACM [CACM]. Overview papers and topics of broad interest appear in IEEE Computer [Comp], IEEE Micro [Micr], and ACM Computing Surveys [CoSu].
Acknowledgments
This text, Computer Architecture: From Microprocessors to Supercomputers, is an outgrowth of lecture notes the author has used for the upper-division undergraduate course ECE 154: Introduction to Computer Architecture at the University of California, Santa Barbara, and, in rudimentary forms, at several other institutions prior to 1988. The text has benefited greatly from keen observations, curiosity, and encouragement of my many students in these courses. A sincere thanks to all of them! Thanks are also due to engineering editors at Oxford University Press (Peter Gordon, who started the project, and Danielle Christensen, who guided it to completion) and to Karen Shapiro, who ably managed the production process. Finally, the granting of permission by Dr. James Larus, of Microsoft Research, for the use of his SPIM simulators is gratefully acknowledged.
General references
The list that follows contains references of two types: (1) books that have greatly influenced the current text and (2) general reference sources for in-depth studies or research. Books and other resources that are relevant to specific chapters are listed in the end-of-chapter bibliographies.
[Arch] WWW Computer Architecture Page, a Web resource kept by the Computer Science Department, University of Wisconsin, Madison, has a wealth of information on architecture-related organizations, groups, projects, publications, events, and people: http://www.cs.wisc.edu/~arch/www/index.html
[CACM] Communications of the ACM, journal published by the Association for Computing Machinery.
[Comp] IEEE Computer, technical magazine published by the IEEE Computer Society.
[CoSu] Computing Surveys, journal published by the Association for Computing Machinery.
[Henn03] Hennessy, J. L., and D. A. Patterson, Computer Architecture: A Quantitative Approach, Morgan Kaufmann, 3rd ed., 2003.
[HPCA] Proceedings of the Symposium(s) on High-Performance Computer Architecture, sponsored by IEEE. The 10th HPCA was held on February 14-18, 2004, in Madrid, Spain.
[ICPP] Proceedings of the International Conference(s) on Parallel Processing, held annually since 1972. The 33rd ICPP was held on August 15-18, 2004, in Montreal, Canada.
[IPDP] Proceedings of the International Parallel and Distributed Processing Symposium(s), formed in 1998 from merging IPPS (held annually beginning in 1987) and SPDP (held annually beginning in 1989). The latest IPDPS was held on April 26-30, 2004, in Santa Fe, New Mexico.
[ISCA] Proceedings of the International Symposium(s) on Computer Architecture, held annually since 1973, usually in May or June. The 31st ISCA was held on June 19-23, 2004, in Munich, Germany.
[JPDC] Journal of Parallel and Distributed Computing, published by Academic Press.
[Micr] IEEE Micro, technical magazine published by the IEEE Computer Society.
[Muel00] Mueller, S. M., and W. J. Paul, Computer Architecture: Complexity and Correctness, Springer, 2000.
[Patt98] Patterson, D. A., and J. L. Hennessy, Computer Organization and Design: The Hardware/Software Interface, Morgan Kaufmann, 2nd ed., 1998.
[Rals03] Ralston, A., E. D. Reilly, and D. Hemmendinger (eds.), Encyclopedia of Computer Science, Wiley, 4th ed., 2003.
[Siew82] Siewiorek, D. P., C. G. Bell, and A. Newell, Computer Structures: Principles and Examples, McGraw-Hill, 1982.
[Sohi98] Sohi, G. (ed.), 25 Years of the International Symposia on Computer Architecture: Selected Papers, ACM Press, 1998.
[Stal03] Stallings, W., Computer Organization and Architecture, Prentice Hall, 6th ed., 2003.
[Swar76] Swartzlander, E. E., Jr (ed.), Computer Design Development: Principal Papers, Hayden, 1976.
[TrCo] IEEE Trans. Computers, journal published by the IEEE Computer Society.
[TrPD] IEEE Trans. Parallel and Distributed Systems, journal published by the IEEE Computer Society.
[Wilk95] Wilkes, M. V., Computing Perspectives, Morgan Kaufmann, 199
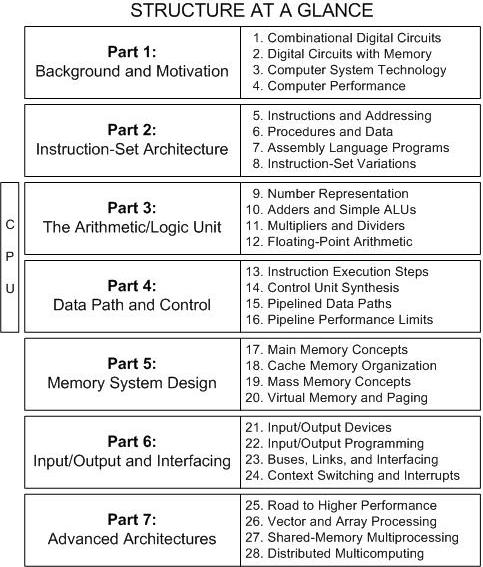
Complete Table of Contents
Note: Each chapter ends with sections entitled "Problems" and "References and Further Readings."
Part 1: Background and Motivation
1 Combinational Digital Circuits ~
1.1 Signals, Logic Operators, and Gates ~
1.2 Boolean Functions and Expressions ~
1.3 Designing Gate Networks ~
1.4 Useful Combinational Parts ~
1.5 Programmable Combinational Parts ~
1.6 Timing and Circuit Considerations
2 Digital Circuits with Memory ~
2.1 Latches, Flip-Flops, and Registers ~
2.2 Finite-State Machines ~
2.3 Designing Sequential Circuits ~
2.4 Useful Sequential Parts ~
2.5 Programmable Sequential Parts ~
2.6 Clocks and Timing of Events
3 Computer System Technology ~
3.1 From Components to Applications ~
3.2 Computer Systems and Their Parts ~
3.3 Generations of Progress ~
3.4 Processor and Memory Technologies ~
3.5 Peripherals, I/O, and Communications ~
3.6 Software Systems and Applications
4 Computer Performance ~
4.1 Cost, Performance, and Cost/Performance ~
4.2 Defining Computer Performance ~
4.3 Performance Enhancement: Amdahl's Law ~
4.4 Performance Measurement vs Modeling ~
4.5 Reporting Computer Performance ~
4.6 The Quest for Higher Performance
Part 2: Instruction-Set Architecture
5 Instructions and Addressing ~
5.1 Abstract View of Hardware ~
5.2 Instruction Formats ~
5.3 Simple Arithmetic and Logic Instructions ~
5.4 Load and Store Instructions ~
5.5 Jump and Branch Instructions ~
5.6 Addressing Modes
6 Procedures and Data ~
6.1 Simple Procedure Calls ~
6.2 Using the Stack for Data Storage ~
6.3 Parameters and Results ~
6.4 Data Types ~
6.5 Arrays and Pointers ~
6.6 Additional Instructions
7 Assembly Language Programs ~
7.1 Machine and Assembly Languages ~
7.2 Assembler Directives ~
7.3 Pseudoinstructions ~
7.4 Macroinstructions ~
7.5 Linking and Loading ~
7.6 Running Assembler Programs
8 Instruction-Set Variations ~
8.1 Complex Instructions ~
8.2 Alternative Addressing Modes ~
8.3 Variations in Instruction Formats ~
8.4 Instruction-Set Design and Evolution ~
8.5 The RISC/CISC Dichotomy ~
8.6 Where to Draw the Line
Part 3: The Arithmetic/Logic Unit
9 Number Representation ~
9.1 Positional Number Systems ~
9.2 Digit Sets and Encodings ~
9.3 Number-Radix Conversion ~
9.4 Signed Integers ~
9.5 Fixed-Point Numbers ~
9.6 Floating-Point Numbers
10 Adders and Simple ALUs ~
10.1 Simple Adders ~
10.2 Carry Propagation Networks ~
10.3 Counting and Incrementation ~
10.4 Design of Fast Adders ~
10.5 Logic and Shift Operations ~
10.6 Multifunction ALUs
11 Multipliers and Dividers ~
11.1 Shift-Add Multiplication ~
11.2 Hardware Multipliers ~
11.3 Programmed Multiplication ~
11.4 Shift-Subtract Division ~
11.5 Hardware Dividers ~
11.6 Programmed Division
12 Floating-Point Arithmetic ~
12.1 Rounding Modes ~
12.2 Special Values and Exceptions ~
12.3 Floating-Point Addition ~
12.4 Other Floating-Point Operations ~
12.5 Floating-Point Instructions ~
12.6 Result Precision and Errors
Part 4: Data Path and Control
13 Instruction Execution Steps ~
13.1 A Small Set of Instructions ~
13.2 The Instruction Execution Unit ~
13.3 A Single-Cycle Data Path ~
13.4 Branching and Jumping ~
13.5 Deriving the Control Signals ~
13.6 Performance of the Single-Cycle Design
14 Control Unit Synthesis ~
14.1 A Multicycle Implementation ~
14.2 Clock Cycle and Control Signals ~
14.3 The Control State Machine ~
14.4 Performance of the Multicycle Design ~
14.5 Microprogramming ~
14.6 Dealing with Exceptions
15 Pipelined Data Paths ~
15.1 Pipelining Concepts ~
15.2 Pipeline Stalls or Bubbles ~
15.3 Pipeline Timing and Performance ~
15.4 Pipelined Data Path Design ~
15.5 Pipelined Control ~
15.6 Optimal Pipelining
16 Pipeline Performance Limits ~
16.1 Data Dependencies and Hazards ~
16.2 Data Forwarding ~
16.3 Pipeline Branch Hazards ~
16.4 Branch Prediction ~
16.5 Advanced Pipelining ~
16.6 Exceptions in a Pipeline
Part 5: Memory System Design
17 Main Memory Concepts ~
17.1 Memory Structure and SRAM ~
17.2 DRAM and Refresh Cycles ~
17.3 Hitting the Memory Wall ~
17.4 Pipelined and Interleaved Memory ~
17.5 Nonvolatile Memory ~
17.6 The Need for a Memory Hierarchy
18 Cache Memory Organization ~
18.1 The Need for a Cache ~
18.2 What Makes a Cache Work? ~
18.3 Direct-Mapped Cache ~
18.4 Set-Associative Cache ~
18.5 Cache and Main Memory ~
18.6 Improving Cache Performance
19 Mass Memory Concepts ~
19.1 Disk Memory Basics ~
19.2 Organizing Data on Disk ~
19.3 Disk Performance ~
19.4 Disk Caching ~
19.5 Disk Arrays and RAID ~
19.6 Other Types of Mass Memory
20 Virtual Memory and Paging ~
20.1 The Need for Virtual Memory ~
20.2 Address Translation in Virtual Memory ~
20.3 Translation Lookaside Buffer ~
20.4 Page Replacement Policies ~
20.5 Main and Mass Memories ~
20.6 Improving Virtual Memory Performance
Part 6: Input/Output and Interfacing
21 Input/Output Devices ~
21.1 Input/Output Devices and Controllers ~
21.2 Keyboard and Mouse ~
21.3 Visual Display Units ~
21.4 Hard-Copy Input/Output Devices ~
21.5 Other Input/Output Devices ~
21.6 Networking of Input/Output Devices
22 Input/Output Programming ~
22.1 I/O Performance and Benchmarks ~
22.2 Input/Output Addressing ~
22.3 Scheduled I/O: Polling ~
22.4 Demand-Based I/O: Interrupts ~
22.5 I/O Data Transfer and DMA ~
22.6 Improving the I/O Performance
23 Buses, Links, and Interfacing ~
23.1 Intra- and Intersystem Links ~
23.2 Buses and Their Appeal ~
23.3 Bus Communication Protocols ~
23.4 Bus Arbitration and Performance ~
23.5 Basics of Interfacing ~
23.6 Interfacing Standards
24 Context Switching and Interrupts ~
24.1 System Calls for I/O ~
24.2 Interrupts, Exceptions, and Traps ~
24.3 Simple Interrupt Handling ~
24.4 Nested Interrupts ~
24.5 Types of Context Switching ~
24.6 Threads and Multithreading
Part 7: Advanced Architectures
25 Road to Higher Performance ~
25.1 Past and Current Performance Trends ~
25.2 Performance-Driven ISA Extensions ~
25.3 Instruction-Level Parallelism ~
25.4 Speculation and Value Prediction ~
25.5 Special-Purpose Hardware Accelerators ~
25.6 Vector, Array, and Parallel Processing
26 Vector and Array Processing ~
26.1 Operations on Vectors ~
26.2 Vector Processor Implementation ~
26.3 Vector Processor Performance ~
26.4 Shared-Control Systems ~
26.5 Array Processor Implementation ~
26.6 Array Processor Performance
27 Shared-Memory Multiprocessing ~
27.1 Centralized Shared Memory ~
27.2 Multiple Caches and Cache Coherence ~
27.3 Implementing Symmetric Multiprocessors ~
27.4 Distributed Shared Memory ~
27.5 Directories to Guide Data Access ~
27.6 Implementing Asymmetric Multiprocessors
28 Distributed Multicomputing ~
28.1 Communication by Message Passing ~
28.2 Interconnection Networks ~
28.3 Message Composition and Routing ~
28.4 Building and Using Multicomputers ~
28.5 Network-Based Distributed Computing ~
28.6 Grid Computing and Beyond
Instructor's Solutions Manual
Preface to the Instructor's Solution Manual:
This manual, which presents solutions to selected problems in the text Computer Architecture: From Microprocessors to Supercomputers (Oxford University Press, 2005, ISBN 0-19-515455-X), is available free of charge to instructors who adopt the text. [Please contact Oxford Univ. Press]. All other teaching material for the text are available from the Web page below which is maintained by the author:
http://www.ece.ucsb.edu/~parhami/text_comp_arch.htm
In the book's Web page, instructors and students can find the following items related to the text:
- Preface; including book's features and general references
- Contents at a glance
- Downloadable presentations covering the seven parts of the text (PowerPoint and PDF files)
- Complete table of contents
- List of corrections and additions for the book and for this manual
The author would appreciate the reporting of any error in the textbook or in this manual, suggestions for additional problems, alternate solutions to solved problems, solutions to other problems, and sharing of teaching experiences. Please e-mail your comments to "parhami at ece dot ucsb dot edu" or send them by regular mail to the author's postal address:
Dept. Electrical & Computer Engineering
University of California
Santa Barbara, CA 93106-9560, USA
Contributions will be acknowledged to the extent possible
List of Errors

This list is presented in three sections. The first section contains a list of critical errors that must be corrected by the reader. The second section contains a list of noncritical corrections and cosmetic improvements. Because they do not affect the reader's understanding of the material, making these corrections is optional. The third section contains a list of errors in, and additions to, the instructor's solutions manual.
Critical errors in the text (must be corrected)
p. 41:
In Table 3.1, "Y yotta" and "y yocto" correspond to 1024 and 10−24, respectively. Insert "Z zetta" and "z zepto" in their place.
p. 48:
In the equation for Die cost, near the middle of the page, replace "Wafer area" with "Usable wafer area." Then, in the subsequent discussion, immediately after "The only variables in the preceding equation are die area and die yield" add this sentence: "Usable wafer area, the part of the wafer that is actually covered by dies, is smaller than its geometric area (see Fig. 3.9)."
p. 69:
In the solution to part c of Example 4.3, the two occurrences of 0.125 should be replaced with 0.25 and 4.5% should be replaced with 10%.
p. 90:
In Figure 5.6, switch the 5-bit values for the rs and rt fields (10000 for rs, 01000 for rt).
p. 92:
In Example 5.2, the second instruction should be: ori $s0,$s0,0x003d
p. 93:
Add the following statement to the end of the middle paragraph that begins with "For the j instruction ...": Given that, in practice, PC is usually incremented very early in the instruction execution cycle (before instruction decoding and execution), we assume that the 4 high-order bits of the incremented PC are used to augment the 26-bit address field.
p. 93:
In Figure 5.9 (middle left), change "From PC" to "From the incremented PC".
p. 96:
In the assembly language program fragment labeled "loop" that begins on line 6, the 6th instruction should be: addi $s1,$s1,1 (the comment part following "#" does not change).
p. 98:
In the column of Table 5.1 headed "Meaning," for the instruction "Set less than," replace "(rs) < (rd)" with "(rs) < (rt)".
p. 109:
On line 5 after Figure 6.5, change "$fp may hold the conent of $fp" to "$fp may hold the content of $sp".
p. 109:
On line −8, 4($fp), 8($fp), and 12($fp) should be changed to −4($fp), −8($fp), and −12($fp).
p. 110:
In the machine language program segment near the top of the page, change the last lw instruction to have the address −4($sp). This is needed because the stack pointer has already been restored to its original value.
p. 116:
In the program within Example 6.4, the machine instruction labled "loop" within the "max" procedure should be corrected to: beq $t0,$a1,ret
p. 137:
On line 6 of Problem 7.8, change [0, 65, 536] to [0, 65 536]; this is an interval notation, with the interval endpoints being at 0 and 65 536, not a list of three numbers.
p. 152:
(This, and the next few errors on pp. 152-153 were brought to the author's attention by Dr. Jim Diamond of Acadia University)
After line 11, that begins with "start:", insert the line:
urisc temp,temp,+1 # temp = 0
p. 152:
Change lines 12 and 13, that follow the line "start: ...", to the following:
urisc temp,src,+1 # temp = −(src)
urisc dest,temp,+1 # dest = −(temp); that is, (src)
p. 152:
On lines −7, −6, −4, and −1, swap the first two arguments that follow urisc (e.g., change "src1,at1" to "at1,src1").
p. 153:
On lines 1, 4, 5, and 7, swap the first two arguments that follow urisc (e.g., change "src2,at2" to "at2,src2").
p. 153:
In Example 8.2, change the solutions to parts d and e to the following:
partd: urisc at1,at1,+1 # at1 = 0
urisc at2,at2,+1 # at2 = 0
urisc at1,src1,+1 # at1 = −(src1)
urisc at2,at1,+1 # at2 = −(at1); that is, (src1)
urisc at2,src2,+2 # if (src1)−(src2) < 0, skip 2 instr's
urisc at1,at1,+1 # at1 = 0
urisc at1,one,label # at1 = −1, to force jump
parte: urisc at1,at1,+1 # at1 = 0
urisc at2,at2,+1 # at2 = 0
urisc at1,src1,+1 # at1 = −(src1)
urisc at2,at1,+1 # at2 = −(at1); that is, (src1)
urisc at2,src2,+5 # if (src1)−(src2) < 0, skip 4 instr's
urisc at1,at1,+1 # at1 = 0
urisc at1,at2,+3 # if (src2)−(src1) < 0, skip 2 instr's
urisc at1,at1,+1 # at1 = 0
urisc at1,one,label # at1 = −1, to force jump
p. 176:
In Problem 9.14, Part c, change the positive number 33.675 to the negative number –33.675.
p. 192:
In the overflow equation, a quarter of the way up from the bottom of the page, the y variable is intended to represent the lower input to the adder of Fig. 10.19, and not the lower input to the ALU (which goes through an XOR gate before entering the adder). One fix to the problem is calling the lower adder input z and replacing the two occurrences of y in the said equation with z. [Thanks to Mr. Ted Obuchowicz of Concordia University for brining this problem to my attention.]
p. 194:
Change the beginning of the introduction to Problem 10.12 thus: "Consider a 24-bit carry network built by cascading 6 copies ...". Change part b to: "Show that using the block widths 3, 4, 5, 5, 4, 3, rather than 4, 4, 4, 4, 4, 4, leads to a faster carry network."
p. 208:
In Figure 11.10a, change the values of y3 and y0 to 1.
p. 212:
The second row of MS cells in Figure 11.14 are missing two right-to-left arrows (compare with other rows).
p. 221:
On line −3, before example 12.1, change "multiplied" to "multiplied by".
p. 232:
In the lower half of Figure 12.10, the fn field should contain 11xxx0, not 000110.
p. 244:
In the column of Table 13.1 headed "Meaning," for the instruction "Set less than," replace "(rs) < (rd)" with "(rs) < (rt)".
p. 250:
In Figure 13.4, the 4 MSBs of PC must be taken from the output of the adder, rather than from the lower input to the adder (i.e., the incremented PC value must be used). See the corrected version of Figure 13.4 in the ppt or pdf presentation for Part IV.
p. 256:
In Problem 13.5, please change "immediate/offset field" to "immediate field" and the subsequent sentence to: "In particular, the width of the jta field can change, as can the width of the branch offset field."
p. 256:
In part b of Problem 13.6, "pairs or rows" should be "pairs of rows".
p. 260:
On line −11, change "The 3-input" to "The upper 3-input".
p. 260:
On line −10, change "The 2-input" to "The 3-input".
p. 260:
On lines −9 and −8, change "cache or output of the ALU" to "cache, output of the ALU, or content of PC".
p. 260:
On lines −7 and −6, delete the sentence that begins with "The reason for having".
p. 261:
(The need for this and several related changes on pp. 260-269 was brought to the author's attention by Dr. Michael P. Frank of FAMU/FSU.) In Figure 14.3, the lower (2-input) multiplexer next to the register file must be changed to a 3-input mux. Inputs 0 and 1 remain as shown; input 2 comes from the PC output. See the corrected version of Figure 14.3 in the ppt or pdf lecture slides for Part 4.
p. 262:
Table 14.1, third in the group of three lines labeled "Register file":
Change "RegInSrc" to "RegInSrc1 , RegInSrc0" and enter "PC" in the column titled "2".
p. 262:
On line −17 that begins with "00", change "SysCallAddr" to "SysCallAddr|00".
p. 262:
On line −13 that begins with "Note that", insert "or SysCallAddr" between "jta" and "with 00". At the end of the line, add the new sentence "Also, PC31-28 refers to the 4 high-order bits of PC after incrementation."
p. 262:
On lines −2 and −1, change "Figure 14.3," to "Figure 13.3." and remove the rest of the sentence, beginning with "except that".
p. 263:
In Table 14.2, rightmost column, after line −7 (second line of jump instruction in cycle 3) add a third line: "(for jal, see Figure 14.4)
p. 264:
In Figure 14.4, next to last line in Notes for State 5: Change "RegInSrc = 1" to "RegInSrc = 2".
p. 265:
On line −5, the equation for RegWrite should be "RegWrite = ControlSt4 ∨ ControlSt8 ∨ (ControlSt5 ∧ jalInst)". Of course, with this change, the signal is no longer just a function of the control state. So, the statement preceding the equations for ALUSrcX and RegWrite must be modified as well.
p. 268:
In Figure 14.6, the field labeled RegInSrc should be expanded from 1 bit to 2 bits (with a horizontal line drawn under the 2-bit field). In the caption, "22-bit" should be changed to "23-bit".
p. 269:
In Table 14.3, the line that begins with "Register control": The four boldface numerical entries should be (from left to right) "10000", "10001", "10101", "11010".
p. 269:
In Table 14.3, the line that begins with "ALU inputs*": The last entry on the right, which is now blank, should include "x10" on top and "(imm)" below it
p. 270:
In Figure 14.8, line 1, remove "PC + 4" (it is redundant)
p. 273:
Problem 14.2, part a: Replace the first two sentences, and the beginning of the third, with: "The multiplexers feeding the register file have three settings each; thus, there are nine combinations when the settings are taken together. For each of these nine ..."
p. 274:
Problem 14.10, part b, should read: Show that even though the performance benefit derived in part a is an increasing function of h, the speedup factor tends to a constant for large h.
p. 274:
Problem 14.10, part d: Delete ", as was the case in part b".
p. 287:
(The need for this and several related changes on pp. 288-290 was brought to the author's attention by Dr. Lou Hafer of Simon Fraser Univ.)
Figure 15.9 needs the following corrections. The pipeline registers between stages 2 and 3 should be extended at the top to include another 32-bit segment whose input is connected to (rt) and whose output is connected to a similar register added between stages 3 and 4. The output of this latter register feeds the data input of the data cache (with the current connection coming from below removed). See the corrected version of Figure 15.9 in the ppt or pdf lecture slides for Part 4.
p. 288:
At the end of the second paragraph, beginning with "Pipeline stage 3" add the sentence: "For sw instruction, the content of rt will be needed in stage 4 and is thus simply carried over in the top pipeline register."
p. 289:
Table 15.1: In the top line of the column headings, change "top(2-3)" to "middle(2-3)" and "top(3-4)" to "middle(3-4)". Place an asterisk after the table caption and add the following note at the bottom of the table: "*Note: Contents of the top pipeline registers between stages 2-3 and 3-4 are irrelevant in this example and are thus not shown."
p. 290:
Figure 15.10 needs the following corrections (same as those for Figure 15.9 on p. 287). The pipeline registers between stages 2 and 3 should be extended at the top to include another 32-bit segment whose input is connected to (rt) and whose output is connected to a similar register added between stages 3 and 4. The output of this latter register feeds the data input of the data cache (with the current connection coming from below removed). See the corrected version of Figure 15.10 in the ppt or pdf lecture slides for Part 4.
p. 294:
Problem 15.3: Change the 2nd instance of "stages versus cycles" to "stages versus instructions".
p. 301:
Table 16.1: Change the two 0s in the column titled "s2matchesd3" to 1s.
p. 302:
[Augmentation to Fig. 16.5, pointed out by Prof. Sachin B. Patkar of IIT Bombay]
In Fig. 16.5, draw the IncrPC register immediately below the Inst Register (as in Figure 15.9 or 15.10). Use the LoadPC signal, which currently controls the loading of the program counter, to also control the loading of both Inst and IncrPC registers. Justification for the change: When PC loading is disabled to cause refetching of the instruction following the data-dependent instruction that created the data hazard, we must also ensure that the previously fetched instruction currently in Inst/IncrPC is not overwritten by the instruction being refetched. Disabling the loading of Inst and IncrPC registers prevents the overwriting of this instruction, which was advanced in the pipeline as a bubble.
p. 302:
[This is related to the previous augmentation to Fig. 16.5]
On lines 4-6 after Figure 16.5, replace the text "and LoadPC signal ... one cycle of delay" with the new text: ", while LoadPC, LoadInst, and LoadIncrPC signals are deasserted so that the program counter is not updated and the instruction that was not allowed to advance is not overwritten."
p. 302:
[This is related to the previous augmentation to Fig. 16.5]
On lines 9-10 after Figure 16.5, replace the text "no LoadPC signal because the PC is" with the new text: "no LoadPC, LoadInst, or LoadIncrPC signal, because the three registers are"
p. 328:
[Pointed out by Professor Donald Bailey, Massey University, New Zealand]
Contents of the ROM in Figure 17.12 should be complemented (0101, 0110, 1101, 0010). Also, in the paragraph immediately following Figure 17.12, change 1 to 0 and 0 to 1.
p. 339:
Example 18.2: In the problem statement, Figure 18.3 is intended, not Figure 18.2.
p. 409:
Problem 21.9, part a, should refer to Example 21.2 (not 21.1).
p. 512:
In the second parallel algorithm, in Courier font near the middle of the page, the assignment statement for Z[j + s] should read Z[j + s] := Z[j] + Z[j + s] (not X[j] + X[j + s]).
Noncritical corrections and cosmetic improvements to the textbook
p. 11:
On line 3 of Section 1.4, change "Part III" to "Part 3".
p. 13:
On line 5, change "If a decoder" to "If an encoder".
p. 17:
In Problem 1.5, line 3, change "in all case" to "in each case".
p. 44:
On line 18, change "FLOPS" to "MFLOPS".
p. 64:
In the three indented paragraphs near the middle of the page, and on line −15, change "Part II" to "Part 2" (one instance), "Part III" to "Part 3" (two instances), and "Part IV" to "Part 4" (three instances).
p. 79:
In the introductory sentence of Problem 4.19, replace "ASCII White" with "ASCI White".
p. 85:
On line 4, change "Part IV" to "Part 4".
p. 105:
The arrow going from Procedure xyz to Procedure abc should point to the instruction immediately after jal xyz, instead of to jr $ra.
p. 109:
On the left edge of Figure 6.5, $fp and the arrow next to it should be moved down by 0.2 cm to point to the first word in the shaded area, rather than to its top boundary.
p. 110:
In the machine language program segment near the top of the page, change the last two sw instructions and the first two lw instructions to have addresses −8($fp), −12($fp), −12($fp), and −8($fp), respectively. Recall that addresses are stable relative to the frame pointer, whereas the use of the stack pointer as shown assumes that the procedure has returned the stack pointer to where it was after the three registers $fp, $ra, $s0 were saved.
p. 117:
On line −8, change "Part III" to "Part 3".
p. 120:
On line 1, change "set overflow" to "with overflow".
p. 125:
At the right edge of Figure 7.2 (in the column labeled fn), the fourth entry from the top, which is 001100, should be 000011. This is because the branch offset (relative to the next instruction) is supplied in words rather than bytes.
p. 126:
On line −2, change "vector or length" to "vector of length".
p. 134:
Near the top of Figure 7.3, the oval superimposed on the menu bar should be elongated to enclose "Window" as well. Also, the leftmost four buttons on the tools bar should be marked with the symbols for "file" (instead of 1), "floppy disk" (instead of <), "document" (instead of ?), and "hand" (instead of |). The rightmost two buttons with "question mark" and "arrow, question mark" are correctly marked. Please refer to the correct version of Figure 7.3 in the lecture slides for Part 2.
p. 134:
On line −4, change "Part IV" to "Part 4".
p. 149:
Near the middle of the page, change "Part IV" to "Part 4".
p. 151:
In the last three lines, replace "operand1" by "source1", "operand2" by "source2" (two instances), and "with the result" by "with the result of subtraction".
p. 165:
In Example 9.5, line 3 of the solution, remove the extra space between the two consecutive 1s (i.e., the bits in 10110101 should be equally spaced).
p. 168:
In Example 9.7, line 3 of the solution, remove the extra space between the two consecutive 1s (i.e., the bits in 10110101 should be equally spaced).
p. 168:
In Example 9.8, line 4 of the solution, remove the extra spaces between the two consecutive 0s and the two consecutive 1s (i.e., the bits in 01001011 should be equally spaced).
p. 169:
On line −1, change "a the sign bit" to "as the sign bit".
p. 176:
In Problem 9.14, part a, change "0, 2, 4, or 8" to "0, 2, 4, and 8".
p. 188:
In Figure 10.4, put a tick mark on the bottom output s[a,b], indicating that it represents a bundle of b − a + 1 signals. Also, add a mux to select the cout signal from one of the two adders as cb+1 based on the value of ca.
p. 204:
On line 8 of Section 11.3, change "Part IV" to "Part 4".
p. 213:
On line 14 of Section 11.6, change "Part IV" to "Part 4".
p. 244:
On line 2 of Section 13.1, change "Part II" to "Part 2".
p. 244:
On the last line, just before Table 13.1, change "filed" to "field".
p. 248:
In Figure 13.3, add arrowhead to all multiplexer inputs for consistency (5 instances).
p. 248:
On line 1, change "some the details" to "some of the details".
p. 261:
In Figure 14.3, add arrowheads to the inputs of the leftmost three multiplexers (for consistency with the others); 8 arrowheads, altogether, after the critical change suggested for this figure has been made.
p. 262:
On line 9, after Table 14.1, change "selects on of the four" to "selects one of the four".
p. 269:
In Figure 14.7, bottom right, there are 20 solid arrows pointing downward and labeled "Control signals to data path"; there should be 21 arrows.
p. 271:
On line 3 of the final paragraph before Section 14.6, change "20 control signals" to "21 control signals".
p. 300:
On line −16, replace "move to stage 3." with "move to stage 3, where it performs an ALU operation."
p. 325:
On line 3, after Figure 17.9, change "Part VII" to "Part 7".
p. 396:
On line 3, after Figure 21.3, change "several time" to "several times".
p. 412:
On the second line of Example 22.1, change "in the early 1980s" to "more than 20 years ago".
p. 434:
On line 12 from the bottom, change "according the control" to "according to the control".
p. 469:
Change the caption of Fig. 25.1 to: "Trend in computational performance per watt of power used in general-purpose processors and DSPs."
Errors in, and additions to, the instructor's solutions manual
p. 15:
In the solution to Problem 5.9, part d is mislabeled as part a.
p. 16:
In the solution to Problem 5.16, part a, register $s3 should be assumed to hold the constant 5256.
p. 17:
In the solution to Problem 5.18, move slt from the second set to the first set of instructions listed.
p. 19:
In the solution to part a of Problem 6.9, change "desires" to "desired".
p. 23:
The solution to part e should consist of the following two instructions:
slt $at,reg,$zero # set $at to 1 if (reg)<0
beq $at,$zero,L # if ($at)=($0), goto L
p. 36:
Remove the redundant part c just before the solution to Problem 11.4.
p. 40:
In the solution to Problem 12.4, remove smudges between the tables.
p. 46:
In the solution to Problem 14.3, remove the first two lines of text (these two lines have been repeated from the problem statement and do not form part of the solution).
p. 53:
In the solution to part b of Problem 16.10 change $s1 to $s2 in the first instruction and $s2 to $s1 in the fourth instruction. An alternate correction is changing bne to beq, but the comments must be changed accordingly and the correspondence with part a is lost.
p. 57:
In the solution to Problem 17.5, line 1, Figure 17.14 should be referenced (not Figure 17.4).
p. 60:
In the solution to Problem 18.10, change the first table entry in the column headed "Offset bits" (part a) to 2; in the last line of the table (part f), switch the numbers 2 and 4.
p. 66:
In the solution to Problem 20.12, change the fourth entry from the bottom in the rightmost table column (part b, Approx LRU) from E1A1B1C1 to E1A1B1C*1. The entries in the next to last row should read (from left to right): E, CDE, CDE*, E1C1D1, ABCE*, BCDE*, D1E*1B0C0. The entries in the last row (Page faults) should read: 9, 10, 9, 10, 8, 10.
Additions to the Text, and Internet Resources

This section includes extended and alternate explanations for some topics in the textbook. Also, updates to the material are presented in the form of new references (both print and electronic) and additional topics/problems. Like the list of errors in the previous section, the items that follow are organized by page numbers in the textbook.
p. 102:
At the top of page, add the new problem: 5.19 Logic instructions (see Problem 5.11 for format)
The following program fragment leads to a branch decision based on the contents of $s0 and $s1. Assuming that the temporary values in $t0 and $t1 are not needed anywhere else in the program, propose a simpler way of achieving the same end result.
and $t0,$s0,$s1
or $t1,$s1,$s0
beq $t0,$t1,done
p. 186:
Before the final (partial) paragraph, add the following explanation.
To better understand the structure of the carry network of Fig. 10.11, pretend that all the lines represent 32-bit numbers. So, instead of each line representing a (g, p) signal pair, it represents a bundle of 32 lines corresponding to an integer. Also, replace the circles with adders. So, the circle now connected to [0, 0] and [1, 1] on its input side and producing [0, 1] on its output would simply be adding two numbers x0 and x1, producing the sum x0 + x1 (note that "plus" means sum here, not logical OR). With this interpretation, the outputs of the circuit, from right to left, are:
x0
x0 + x1
x0 + x1 + x2
x0 + x1 + x2 + x3
...
These are known as "prefix sums", given that the expressions shown are "prefixes" of x0 + x1 + x2 + x3 + ... + x[k−1]. So, if you design a "parallel prefix sum" circuit (a circuit that computes all the prefix sums in parallel), you can convert it to a carry network by simply replacing the numbers with (g, p) signal pairs and the adders with the "carry operator". There is only one catch: whereas addition is commutative, meaning that x0 + x1 = x1 + x0, the carry operation is not. So, the parallel prefix sum circuit can be converted to a carry network only if it does not group the numbers out of order. For example, if the circuit computes x0 + x1 + x2 + x3 via the grouping (x0 + x2) + (x1 + x3), it will not correspond to a carry network.
p. 312:
Add the new problem: 16.18 Data forwarding and hazard detection
In our discussion of data forwarding (Figure 16.4) we considered supplying the most recent or up-to-date version of register data only to the ALU. Because the content of a register is also used in a sw instruction, forwarding must be extended to the data cache unit as well.
a. Discuss the design of a forwarding unit that ensures correct data input to the data cache.
b. Do we need to extend the data hazard detector of Figure 16.5 for this purpose as well?
p. 352:
At the top of the page, add the new problem: 18.18 Augmented Caching Schemes
Because direct-mapped caches are prone to numerous conflict misses in worst-case scenarios when several often-used pieces of data contend for the same cache line, a number of caching schemes have been developed in which a small fully associative cache augments a direct-mapped one. In one such scheme, a replaced line from the direct-mapped cache is moved to a fairly small, fully associative victim cache [Joup90], where it can be accessed rapidly in the event that it is needed shortly after replacement. Another augmented scheme uses a fully associative assist cache [Kurp94] which holds high-utility data, beginning with their first use, with replaced data moved to a direct-mapped cache.
a. Describe how the use of a small victim cache can lead to a significant reduction in the number of main memory accesses.
b. Repeat part a for an assist cache.
c. Briefly compare the organization, benefits, and drawbacks of victim and assist caches.
[Also add corresponding index entries for the added problem 18.18: Assist cache. Augmented cache. Cache, assist. Cache, victim. Victim cache.]
p. 352:
Add the following new references and further readings:
[Joup90] Jouppi, N.P., "Improving Direct-Mapped Cache Performance by the Addition of a Small Fully-Associative Cache and Prefetch Buffers," Proc. 17th Int'l Symp. Computer Architecture, 1990, pp. 364-373.
[Kurp94] Kurpanek, G., K. Chan, J. Zheng, E. DeLano, and W. Bryg, "PA7200: A PA-RISC Processor with Integrated High Performance MP Bus Interface," Proc. CompCon, February 1994, pp. 375-382.
[Pier99] Peir, J.-K., W.W. Hsu, and A.J. Smith, "Functional Implementation Techniques for CPU Cache Memories," IEEE Trans. Computers, Vol. 48, No. 2, pp. 100-110, February 1999.
p. 367:
A very readable account of developments in probe storage (nano- and MEM-based mass memory), that complements [Vett02] already cited, appeared in the March 2005 issue of IEEE Spectrum (Vol. 42, No. 3, pp. 32-39). In this article [Gold05], entitled "The Race to the Bottom," Harry Goldstein sketches the race between IBM and a small start-up company (http://www.nanochip.com), to introduce the first commercial product offering mass memory on a chip.
p. 370:
Add the new reference:
[WWW] For comprehensive information about disk memory technology, see http://www.storageview.com/guide/
p. 425:
At the end of Section 22.6, add: An effort to merge a variety of proprietary processor buses, local I/O buses, and backplane buses into a low-cost interconnect scheme for embedded systems was undertaken by the RapidIO Trade Association (since 2000; members include Alcatel, Ericsson, Freescale/Motorola, Lucent, TI, Tundra). The resulting open standard uses packet-based communication involving request, response, and ack packets. A request/response packet may hold 1-256 B of data payload. Typical overhead per packet is 10-16 B; an ack packet uses a total of 4 B. For further information, see:
[Full05] Fuller, S., RapidIO: The Embedded System Interconnect, Wiley, 2005; or
http://www.rapidio.org/education/
p. 480:
After the last complete paragraph -- Examples of applications that can benefit from the greater computational power of graphics processors are discussed in a short article:
[Mano05] Manocha, D., "General-Purpose Computations Using Graphics Processors," IEEE Computer, Vol. 38, No. 8, pp. 85-88, August 2005.
Translated Editions

Parhami, B., Arquitectura de Computadoras: De los Microprocesadores a las Supercomputadoras, McGraw-Hill Mexico,
2007, ISBN 9701061462 (Spanish translation by A. V. Mena).
McGraw-Hill Mexico's website for the Spanish edition