
Menu:
Behrooz Parhami's ECE 254B Course Page for Winter 2022
Adv. Computer Architecture: Parallel Processing
Page last updated on 2022 March 22
Enrollment code: 13540
Prerequisite: ECE 254A (can be waived, but ECE 154B is required)
Class meetings: MW 10-11, Phelps 1431 (inverted classroom)
Instructor: Professor Behrooz Parhami
Open office hours: MW 11-11:30, Phelps 1431; W 1-2, HFH 5155
Course announcements: Listed in reverse chronological order
Course calendar: Schedule of lectures, homework, exams, research
Homework assignments: Five assignments, worth a total of 40%
Exams: None for winter 2022
Research paper and poster: Worth 60%
Research paper guidlines: Brief guide to format and contents
Poster presentation tips: Brief guide to format and structure
Policy on academic integrity: Please read very carefully
Grade statistics: Range, mean, etc. for homework and exam grades
References: Textbook and other sources (Textbook's web page)
Lecture slides: Available on the textbook's web page
Miscellaneous information: Motivation, catalog entry, history
Course Announcements
 2022/03/22: The winter 2022 offering of ECE 254B (Parallel Processing) is officially over and grades have been reported to the Registrar. Over the next couple of days, I will send you feedback on your research papers and posters, including your research grade & course grade. As short as the spring break is, I hope it is enough for you to refresh and re-energize for the spring quarter. I will be on sabbatical leave during spring, but will be in Santa Barbara for the most part and will remain reachable via e-mail (and Zoom, if needed), in case you want to discuss technical and academic matters. Take care, and stay safe!
2022/03/22: The winter 2022 offering of ECE 254B (Parallel Processing) is officially over and grades have been reported to the Registrar. Over the next couple of days, I will send you feedback on your research papers and posters, including your research grade & course grade. As short as the spring break is, I hope it is enough for you to refresh and re-energize for the spring quarter. I will be on sabbatical leave during spring, but will be in Santa Barbara for the most part and will remain reachable via e-mail (and Zoom, if needed), in case you want to discuss technical and academic matters. Take care, and stay safe!
2022/03/06: The coming week will be a research-focus week. There will be no inverted classes, but I will be present in our regular classroom, from 10:00 to 11:30 to answer any questions you may have. Hope you have enjoyed and learned from the lectures and homework assignments for this course and that you find the research focus instructive and rewarding over the next 10 days. An interesting IEEE Central Coast Section tech talk by UCSB's Dr. Tim Sherwood, under the title "Temporal Computing: From Machine Learning to Superconducting Logic," is coming up on W 3/16, 6:00 PM PDT (info & free registration).
2022/02/26: By Wednesday of this week, we will be done with course lectures and homework assignments. The following week is devoted to research, although I will hold optional inverted classes for questions and consultation. Your final list of research references and a provisional abstract are due by M 2/28 (any time).
2022/02/21: HW5, the last one for the course, has been posted to the homework area below. It will be due by 10:00 AM on M 3/02. The next research milestone will be submission of your final list of references, along with a provisional abstract, by M 2/28. You will finish up your research project by submitting a PDF file of your poster (there will be no oral presentation) by W 3/09 and the complete paper in a single PDF file by W 3/16.
2022/02/11: Grade stats for HW1-HW3 are posted. Please submit your homework solutions and other material in a single PDF file. Multiple files or other formats (such as MS Word, Google docs, zip, or indirect links) create problems for me, given how I process homework submissions (often on the go, with no broadband access). The next research milestone will be submission of your final list of references and a provisional abstract by M 2/28 (any time).
2022/02/05: HW4 has been posted to the homework area below. It will be due on W 2/16. The next research milestone will be submission of a preliminary list of references by W 2/09 (any time). This list is for me to know that you have made progress in identifying a suitable collection of sources for your work and to determine whether you need guidance in this regard. The list is preliminary in the sense that you can add new sources as you identify them, or remove existing sources, if they prove less useful.
2022/01/29: Even though I am personally delighted to return to in-person teaching this coming week, there are some apprehensions on the part of both students and faculty, given the recent COVID surge. Please feel free to share with me your thoughts on this very important issue, in class or outside class. A graduate course is challenging even under normal conditions. I want to make sure we do the best we can in learning the course material, despite the challenging conditions we face.
We have no deadlines this week. Hope you are making progress on your research project. Please let me know if you run into problems identifying suitable references. Your preliminary list of references will be due on W 2/09.
UCSB Library will be handing out free copies of the UCSB Reads 2022 selection, Ted Chiang's Exhalation: Stories, on T 2/01, beginning at 10:00 AM, to students in front of the West Entrance to the Library. I have written a review of the book on GoodReads.
2022/01/25: HW3 has been posted to the homework area below. It will be due on M 2/07.
2022/01/20: I have assigned research topics to 11 students. Those of you who will be submitting your top-4 list of topic preferences within the next couple of days should avoid the already-assigned topics to maximize your chances of getting one of your specified topics. Here is a report on my January 19, 2022, lecture entitled "Interconnection Networks for Parallel Processors and Data Centers," which includes links to my slides and the recorded lecture.
2022/01/17: HW2 has been posted to the homework area below. Reminders for W 1/19: Your top-4 research topic preferences are due and I will give a talk for IEEE CCS on "Interconnection Networks for Parallel Processors and Data Centers."
2022/01/11: Research topics for winter 2022 have been defined. Each student please send me the top 4 topic choices, in order of preference, by the W 1/19 deadline. If you need a couple of extra days to decide, that's okay, but I will start making assignments the day after the deadline. So, later submissions risk having their top choices already taken.
2022/01/08: In view of additional challenges due to the rapid spread of COVID-19's omicron variant, remote instruction at UCSB has been extended to the end of January, pending additional campus-wide review.
2022/01/04: HW1 has been posted to the homework area below. I am working on defining research problems for winter 2022 and should be able to complete this task by W 1/12. As I mentioned in the first flipped class, there may be occasional inconsistencies between what I say in the lecture videos and what you see on this page (e.g., regarding course requirements). In such cases, the contents of this page take precedence. I reiterate what I said about the importance of class participation (posing questions and offering comments) in a graduate-level course. I am still awaiting the receipt of photos from 4 of the 23 class students.
2021/12/23: Due to public-health concerns, Winter 2022 courses at UCSB will be offered in on-line format, until further notice. I will send you a Zoom link for our inverted classes and office hours via a GauchoSpace announcement. If you don't receive an e-mail from me via GauchoSpace, because you joined the class late, please contact me or see the "Instructor Announcements" section of the course page on GauchoSpace. See you virtually in the first inverted class on Monday, January 3, 2022, 10:00-11:00 AM. Please make every effort to attend the first class-session (having watched Lecture 1 beforehand), because I will discuss important details about how I will conduct the class and the role of attendance/participation in evaluating your work. Stay well!
[P.S.: Those of you with no photo on GauchoSpace, please either add a photo to your profile or send me a jpg photo attached to an e-mail message before the first class. Thanks.]
2021/11/26: Welcome to the ECE 254B web page for winter 2022! As of today, 16 students have signed up for the course. I will send out an introductory e-mail in December and will issue periodic reminders and announcements from GauchoSpace. However, my primary mode of communication about the course will be through this Web page. Make sure to consult this "Announcements" section regularly. Looking forward to meeting all of you!
Course Calendar

Course lectures and homework assignments have been scheduled as follows. This schedule will be strictly observed. In particular, no extension is possible for homework due dates; please start work on the assignments early. Each lecture covers topics in 1-2 chapters of the textbook. Chapter numbers are provided in parentheses, after day & date. PowerPoint and PDF files of the lecture slides can be found on the textbook's web page.
Day & Date (book chapters) Lecture topic [HW posted/due] {Research milestones}
M 01/03 (1) Introduction to parallel processing Lecture 1
W 01/05 (2) A taste of parallel algorithms [HW1 posted; chs. 1-4] Lecture 2
M 01/10 (3-4) Complexity and parallel computation models Lecture 3
W 01/12 (5) The PRAM shared-memory model and basic algorithms {Research topics issued} Lecture 4
M 01/17 No lecture: Martin Luther King Holiday [HW1 due] [HW2 posted; chs. 5-6C]
W 01/19 (6A) More shared-memory algorithms {Research topic preferences due} Lecture 5
M 01/24 (6B-6C) Shared memory implementations and abstractions {Research assignments} Lecture 6
W 01/26 (7) Sorting and selection networks [HW2 due] [HW3 posted; chs. 7-8C] Lecture 7
M 01/31 (8A) Search acceleration circuits Lecture 8
W 02/02 (8B-8C) Other circuit-level examples Lecture 9
M 02/07 (9) Sorting on a 2D mesh or torus architectures [HW3 due] [HW4 posted; chs. 9-12] Lecture 10
W 02/09 (10) Routing on a 2D mesh or torus architectures {Priliminary references due} Lecture 11
M 02/14 (11-12) Other mesh/torus concepts Lecture 12
W 02/16 (13) Hypercubes and their algorithms [HW4 due] Lecture 13
M 02/21 No lecture: President's Day Holiday [HW5 posted; chs. 13-16]
W 02/23 (14) Sorting and routing on hypercubes Lecture 14
M 02/28 (15-16) Other interconnection architectures {Final ref's & provisional abstract due} Lecture 15
W 03/02 (17) Network embedding and task scheduling [HW5 due] Lecture 16
M 03/07 No lecture: Research focus week
W 03/09 Poster presentation session {Research poster PDF file due by midnight}
W 03/16 {Research paper PDF file due by midnight}
T 03/22 {Course grades due by midnight}
Homework Assignments
 - Turn in solutions as a single PDF file attached to an e-mail sent by the due date/time.
- Turn in solutions as a single PDF file attached to an e-mail sent by the due date/time.
- Because solutions will be handed out on the due date, no extension can be granted.
- Include your name, course name, and assignment number at the top of the first page.
- If homework is handwritten and scanned, make sure that the PDF is clean and legible.
- Although some cooperation is permitted, direct copying will have severe consequences.
Homework 1: Introduction, complexity, and models (Chs. 1-4; due M 2022/01/17, 10:00 AM)
Do the following problems from the textbook: 1.7, 1.11, 1.25 (defined below), 2.5, 3.2, 3.7ab, 4.11ab
1.25 World's most-powerful supercomputers Since the last revisions to the textbook and lecture slides, the most-powerful supercomputers in the world may have changed. Consult the Top500 Web site to find out and report in a table the characteristics of the current top-3 supercomputers. Discuss in a short paragraph how close we are to reaching the next performance milestone (the milestones being 1000^m flops, where, for example, m = 6 corresponds to exaflops or 10^18 flops) and when that next milestone may be reached.
Homework 2: Shared-memory parallel processing (Chs. 5-6C; due W 2022/01/26, 10:00 AM)
Do the following problems from the textbook: 5.5 (corrected), 5.10, 6.4, 6.9b, 6C.1 (defined below), 16.13
5.5 Semigroup computation on a PRAM [Correction] Both instances of i + s in the problem statement should be j + s.
6C.1 An implementation of transactional memory By referring to the following IBM Web page and reading [Wang12], discuss in one typed page (single-spacing okay) how transactional memory has been implemented on IBM Blue Gene/Q.
[Transactional-memory subpage of IBM's XL Fortran for Blue Gene/Q]
[Wang12] A. Wang et al., "Evaluation of Blue Gene/Q Hardware Support for Transactional Memories," Proc. 21st Int'l Conf. Parallel Architectures and Compilation Techniques, pp. 127-136, 2012.
Homework 3: Circuit model of parallel processing (Chs. 7-8C; due M 2022/02/07, 10:00 AM)
Do the following problems from the textbook: 7.2ab, 7.6, 7.13, 8.9, 8.18 (defined below), 8.24 (defined below)
8.18 Distributed dictionary machine The p processors of a linear array hold n records in sorted order such that the leftmost processor holds the records with the smallest keys. As the processors compute, they produce new records or cause records to be deleted. Discuss in high-level terms a protocol to be followed by the processors for insertion and deletion of records such that the sorted order of the records is maintained and the processor loads (number of records held) are roughly balanced over the long run.
8.24 Accelerator architectures Read the paper [Hwu18] and present in one PowerPoint slide the notion of accelerator architectures, how they have evolved over the years, and why they are in broad use today.
[Hwu18] Hwu, W.-M. and S. Patel, "Accelerator Architectures—A Ten-Year Retrospective," IEEE Micro, Vol. 38, No. 6, pp. 56-62, November-December 2018.
Homework 4: Mesh/torus-connected parallel computers (Chs. 9-12; due W 2022/02/16, 10:00 AM)
Do the following problems from the textbook: 9.2, 9.21 (defined below), 10.9, 11.1, 11.5, 12.4ab
9.21 The shearsort algorithm Using the result of the analysis for optimized shearsort in Section 9.3, compare the speed of shearsort for sorting 4m^2 elements (m is a power of 2) on the following three meshes:
a. Tall, 4m × m
b. Square, 2m × 2m
c. Wide, m × 4m
Homework 5: Hypercubic & other parallel computers (Chs. 13-16; due M 2022/03/02, 10:00 AM)
Do the following problems from the textbook: 13.2, 13.21 (defined below), 14.4, 15.2abc, 16.3abc, 16.28 (defined below)
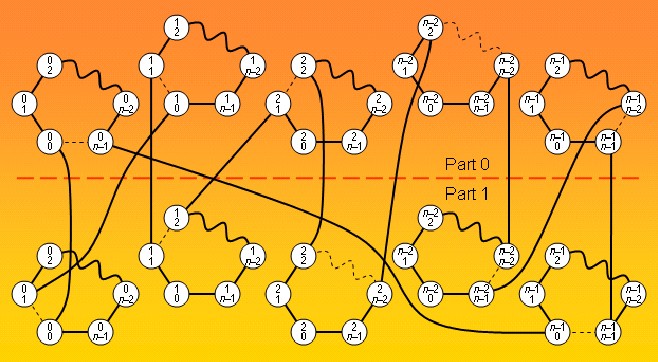
13.21 Embedding parameters The three examples in Fig. 13.2 suggest that dilation, congestion, and load factor are orthogonal parameters in the sense that knowing two of them does not provide much, if any, information about the third. Reinforce this conclusion by constructing, when possible, additional examples for which dilation, congestion, and load factor are (respectively):
a. 1, 1, 2
b. 1, 2, 1
c. 2, 1, 1
d. 2, 1, 2
e. 2, 2, 2
16.28 Topological properties of product graphs Let graphs G and H contain a and b edge-disjoint spanning trees, respectively. Show that the product graph G × H contains at least a + b – 1 edge-disjoint spanning trees.
[Ku03] Ku, S.-C., B.-F. Wang, and T.-K. Hung, "Constructing Edge-Disjoint Spanning Trees in Product Networks," IEEE Trans. Parallel and Distributed Systems, Vol. 14, No. 3, pp. 213-221, March 2003.
Sample Exams and Study Guides (not applicable to winter 2022)

The following sample exams using problems from the textbook are meant to indicate the types and levels of problems, rather than the coverage (which is outlined in the course calendar). Students are responsible for all sections and topics, in the textbook, lecture slides, and class handouts, that are not explicitly excluded in the study guide that follows the sample exams, even if the material was not covered in class lectures.
Sample Midterm Exam (105 minutes) (Chapters 8A-8C do not apply to this year's midterm)
Textbook problems 2.3, 3.5, 5.5 (with i + s corrected to j + s), 7.6a, and 8.4ac; note that problem statements might change a bit for a closed-book exam.
Midterm Exam Study Guide
The following sections are excluded from Chapters 1-7 of the textbook to be covered in the midterm exam, including the three new chapters named 6A-C (expanding on Chpater 6):
3.5, 4.5, 4.6, 6A.6, 6B.3, 6B.5, 6C.3, 6C.4, 6C.5, 6C.6, 7.6
Sample Final Exam (150 minutes) (Chapters 1-7 do not apply to this year's final)
Textbook problems 1.10, 6.14, 9.5, 10.5, 13.5a, 14.10, 16.1; note that problem statements might change a bit for a closed-book exam.
Final Exam Study Guide
The following sections are excluded from Chapters 8A-19 of the textbook to be covered in the final exam:
8A.5, 8A.6, 8B.2, 8B.5, 8B.6, 9.6, 11.6, 12.5, 12.6, 13.5, 15.5, 16.5, 16.6, 17.1, 17.2, 17.6, 18.6, 19
Research Paper and Presentation
 Our research focus this quarter will be on interconnection networks, which constitute important components for realizing efficient, large-scale parallel processors. A good starting point for your studies is my lecture entitled "Interconnection Networks for Parallel Processing and Data Centers," delivered on 2022/01/19, at 6:30 PM PST, as part of IEEE Computer Society's Distinguished Visitors Program. [Register to get the Zoom link]
Our research focus this quarter will be on interconnection networks, which constitute important components for realizing efficient, large-scale parallel processors. A good starting point for your studies is my lecture entitled "Interconnection Networks for Parallel Processing and Data Centers," delivered on 2022/01/19, at 6:30 PM PST, as part of IEEE Computer Society's Distinguished Visitors Program. [Register to get the Zoom link]
Our textbook covers some general ideas on interconnection networks in Chapter 16 and many example networks throughout the book. In addition, you will find the first two of the following references useful. The first one has good theoretical coverage, while the second one focuses on networks used in actual top-of-the-line supercomputers. The third reference is listed for its relative recency. I have not been able access the paper in order to assess it.
[Xu13] J. Xu, Topological Structure and Analysis of Interconnection Networks, Springer, 2013.
[Trob16] R. Trobec, R. Vasiljevic, M. Tomasevic, V. Milutinovic, R. Beivide, and M. Valero, "Interconnection Networks in Petascale Computer Systems: A Survey," ACM Computing Surveys, Vol. 49, No. 3, pp. 1-24, 2016.
[Moud21] M. Moudi and M. Othman, "A Survey on Emerging Issues in Interconnection Networks," Int'l J. Internet Technology and Secured Transactions, Vol. 11, No. 2, pp. 131-159, 2021.
Here is a list of research paper titles, presented in five sections. For topic selection, you should give me your first to fourth choices among the topics that follow by the "Research topic preferences due" deadline. I will then assign a topic to you within a few days, based on your preferences and those of your classmates. Sample references follow the titles to help define the scope and serve as starting points.
Dependability Attributes
D1. Node- and Edge-Connectivity of Networks (Assigned to: Zexi Liu)
[Gutm06] I. Gutman and S. Zhang, "Graph Connectivity and Wiener Index," Bulletin (Academie Serbe des Sciences et des Arts. Classe des Sciences Mathematiques et Naturelles. Sciences mathematiques), pp. 1-5, 2006.
[Wigd92] A. Wigderson, "The Complexity of Graph Connectivity," Proc. Int'l Symp. Mathematical Foundations of Computer Science, Springer, pp. 112-132, 1992.
D2. Fault-Diameter of Interconnection Networks (Assigned to: TBD)
[Kris87] M. S. Krishnamoorthy and B. Krishnamurthy, "Fault Diameter of Interconnection Networks," Computers & Mathematics with Applications, Vol. 13, Nos. 5-6, pp. 577-582, 1987.
[Xu02] J.-M. Xu and X. Xie, "On Fault-Tolerant Diameter and Wide Diameter of Graphs," J. University of Science and Technology of China, Vol. 32, No. 2, pp. 135-139, 2002.
D3. Wide-Diameter of Interconnection Networks (Assigned to: TBD)
[Xu02] J.-M. Xu and X. Xie, "On Fault-Tolerant Diameter and Wide Diameter of Graphs," J. University of Science and Technology of China, Vol. 32, No. 2, pp. 135-139, 2002.
[Gao15] S. Gao and C. Zhu, "Wide Diameter for Two Families of Interconnection Networks," Wuhan University J. Natural Sciences, Vol. 20, No. 5, pp. 375-380, 2015.
D4. Parallel Disjoint Paths in Networks (Assigned to: Noah De Los Santos)
[Iqba15] F. Iqbal and F. A. Kuipers, "Disjoint Paths in Networks," Wiley Encyclopedia of Electrical and Electronics Engineering, 2015.
[Ling14] S. Ling and W. Chen, "Node-to-Set Disjoint Paths in Biswapped Networks," The Computer J., Vol. 57, No. 7. pp. 953-967, 2014.
D5. Modeling of Interconnection Network Reliability (Assigned to: Sam Babichenko)
[Dash12] R. K. Dash, N. K. Barpanda, P. K. Tripathy, and C. R. Tripathy, "Network Reliability Optimization Problem of Interconnection Network Under Node-Edge Failure Model," Applied Soft Computing, Vol. 12, No. 8, pp. 2322-2328, 2012.
[MdYu16] N. A. Md Yunus, M. Othman, Z. Mohd Hanapi, and K. Y. Lun, K.Y., "Reliability Review of Interconnection Networks," IETE Technical Review, Vol. 33, No. 6, pp. 596-606, 2016.
Network Classes
N1. Swapped and Biswapped Networks (Assigned to: TBD)
[Yeh96] C. H. Yeh and B. Parhami, "Swapped Networks: Unifying the Architectures and Algorithms of a Wide Class of Hierarchical Parallel Processors," Proc. Int'l Conf. Parallel and Distributed Systems, pp. 230-237, 1996.
[Xiao11] W. Xiao, B. Parhami, W. Chen, M. He, and W. Wei, "Biswapped Networks: A Family of Interconnection Architectures with Advantages over Swapped or OTIS Networks," Int'l J. Computer Mathematics, Vol. 88, No. 13, pp. 2669-2684, 2011.
N2. Constant-Diameter Networks (Assigned to: Nazerke Turtayeva)
[Parh05] B. Parhami and M. Rakov, "Perfect Difference Networks and Related Interconnection Structures for Parallel and Distributed Systems," IEEE trans. Parallel and Distributed Systems, Vol. 16, No. 8, pp. 714-724, 2005.
[Kita16] T. Kitasuka and M. Iida, "A Heuristic Method of Generating Diameter 3 Graphs for Order/Degree Problem," Proc. 10th IEEE/ACM Int'l Symp. Networks-on-Chip (NOCS), pp. 1-6, 2016.
N3. Chordal-Ring Networks (Assigned to: Jackie Burd)
[Bujn03] S. Bujnowski, B. Dubalski, and A. Zabludowski, "Analysis of Chordal Rings," Mathematical Techniques and Problems in Telecommunications, pp. 257-279, 2003.
[Parh99] B. Parhami and D.-M. Kwai, "Periodically Regular Chordal Rings," IEEE Trans. Parallel and Distributed Systems, Vol. 10, No. 6, pp. 658-672, 1999.
N4. Low- vs. High-Dimensional Mesh Networks (Assigned to: Rhys Gretsch)
[Dall90] W. J. Dally, "Performance Analysis of k-ary n-cube Interconnection Networks," IEEE Trans. Computers, Vol. 39, No. 6, pp. 775-785, 1990.
[Parh04] B. Parhami and D. M. Kwai, "Comparing Four Classes of Torus-Based Parallel Architectures: Network Parameters and Communication Performance," Mathematical and Computer Modelling, Vol. 40, Nos. 7-8, pp. 701-720, 2004.
N5. Variations on the Fat-Tree Network (Assigned to: Yiliang Chen)
[Jain17] N. Jain, A. Bhatele, L. H. Howell, D. Bohme, I. Karlin, E. A. Leon, M. Mubarak, N. Wolfe, T. Gamblin, and M. L. Leininger, "Predicting the Performance Impact of Different Fat-Tree Configurations," Proc. Int'l Conf. High Performance Computing, Networking, Storage and Analysis, pp. 1-13, 2017.
[Wang12] Z. Wang, J. Xu, X. Wu, Y. Ye, W. Zhang, M. Nikdast, X. Wang, and Z. Wang, Z., "Floorplan Optimization of Fat-Tree-Based Networks-on-Chip for Chip Multiprocessors," IEEE Trans. Computers, Vol. 63, No. 6, pp. 1446-1459, 2012.
Packaging and Layout
P1. Layout of High-Dimensional Mesh Networks (Assigned to: TBD)
[Weld09] A. Y. Weldezion, M. Grange, D. Pamunuwa, Z. Lu, A. Jantsch, R. Weerasekera, and H. Tenhunen, "Scalability of Network-on-Chip Communication Architecture for 3-D Meshes," Proc. 3rd ACM/IEEE Int'l Symp. Networks-on-Chip, pp. 114-123, 2009.
[Fors11] M. Forsell, V. Leppanen, and M. Penttonen, "Cost of Sparse Mesh Layouts Supporting Throughput Computing," Proc. 14th Euromicro Conf. Digital System Design, pp. 316-323, 2011.
P2. Layout of Multistage Interconnection Networks (Assigned to: TBD)
[Manu07] P. Manuel, K. Qureshi, A. William, and A. Muthumalai, "VLSI Layout of Benes Networks," J. Discrete Mathematical Sciences and Cryptography, Vol. 10, No. 4, pp. 461-472, 2007.
[Yeh00] C. H. Yeh, B. Parhami, E. A. Varvarigos, and H. Lee, "VLSI Layout and Packaging of Butterfly Networks," Proc. 12th Annual ACM Symp. Parallel Algorithms and Architectures, pp. 196-205, 2000.
P3. Design Considerations for Networks on Chip (Assigned to: Richard Boone)
[Beni02] L. Benini and G. De Micheli, "Networks on Chip: A New Paradigm for Systems on Chip Design," Proc. Conf. Design, Automation and Test in Europe, pp. 418-419, 2002.
[Bolo04] E. Bolotin, I. Cidon, R. Ginosar, and A. Kolodny, "Cost Considerations in Network on Chip," Integration, Vol. 38, No. 1, pp. 19-42, 2004.
P4. Energy for On-Chip vs. Off-Chip Network Links (Assigned to: TBD)
[Yayl98] G. I. Yayla, P. J. Marchand, and S. C. Esener, "Speed and Energy Analysis of Digital Interconnections: Comparison of On-Chip, Off-Chip, and Free-Space Technologies," Applied Optics, Vol. 37, No. 2, pp. 205-227, 1998.
[Sikd16] M. A. I. Sikder, "Emerging Technologies in On-Chip and Off-Chip Interconnection Network," Doctoral dissertation, Ohio University, 2016.
P5. Packaging Advantages of Hierarchical Networks (Assigned to: Destin Wong)
[Ragh95] M. T. Raghunath and A. Ranade, "Designing Interconnection Networks for Multi-Level Packaging," VLSI Design, Vol. 2, No. 4, pp. 375-388, 1995.
[Unde12] K. D. Underwood and E. Borch, "Exploiting Communication and Packaging Locality for Cost-Effective Large Scale Networks," Proc. 26th ACM Int'l Conf. Supercomputing, pp. 291-300, 2012.
Routing Algoirthms
R1. Oblivious Network Routing and Its Limitations (Assigned to: Jimmy Kraemer)
[Iyen15] S. S. Iyengar and K. G. Boroojeni, Oblivious Network Routing: Algorithms and Applications, MIT Press, 2015.
[Towl02] B. Towles and W. J. Dally, "Worst-Case Traffic for Oblivious Routing Functions," Proc. 14th Annual ACM Symp. Parallel Algorithms and Architectures, pp. 1-8, 2002.
R2. Adaptive Routing in Networks (Assigned to: Kerr Ding)
[Duat95] J. Duato, "A Necessary and Sufficient Condition for Deadlock-Free Adaptive Routing in Wormhole Networks," IEEE Trans. Parallel and Distributed Systems, Vol. 6, No. 10, pp. 1055-1067, 1995.
[Pere17] D. Perepelkin and M. Ivanchikova, "Improved Adaptive Routing Algorithm in Distributed Data Centers," Advances in Electrical and Electronic Engineering, Vol. 15, No. 3, pp. 502-508, 2017.
R3. Table-Assisted Routing in Networks (Assigned to: Ci-Chian Lu)
[Bose14] A. Bose, P. Ghosal, and S. P. Mohanty, "A Low Latency Scalable 3D NoC Using BFT Topology with Table Based Uniform Routing," Proc. IEEE Computer Society Annual Symp. VLSI, pp. 136-141, 2014.
[Wang09] L. Wang, H. Song, Y. Jiang, and L. Zhang, "A Routing-Table-Based Adaptive and Minimal Routing Scheme on Network-on-Chip Architectures," Computers & Electrical Engineering, Vol. 35, No. 6, pp. 846-855, 2009.
R4. Deadlock-Free Routing in Networks (Assigned to: TBD)
[Duat01] J. Duato and T. M. Pinkston, "A General Theory for Deadlock-Free Adaptive Routing Using a Mixed Set of Resources," IEEE Trans. Parallel and Distributed Systems, Vol. 12, No. 12, pp. 1219-1235, 2001.
[Duat95] J. Duato, "A Necessary and Sufficient Condition for Deadlock-Free Adaptive Routing in Wormhole Networks," IEEE Trans. Parallel and Distributed Systems, Vol. 6, No. 10, pp. 1055-1067, 1995.
R5. Broadcasting and Multicasting in Networks (Assigned to: TBD)
[Defa04] X. Defago, A. Schiper, and P. Urban, "Total Order Broadcast and Multicast Algorithms: Taxonomy and Survey," ACM Computing Surveys, Vol. 36, No. 4, pp. 372-421, 2004.
[Haru06] H. A. Harutyunyan and B. Shao, "An Efficient Heuristic for Broadcasting in Networks," J. Parallel and Distributed Computing, Vol. 66, No. 1, pp. 68-76, 2006.
Theory and Foundations
T1. The Degree-Diameter Problem in Networks (Assigned to: Swetha Pillai)
[Mill12] M. Miller and J. Siran, "Moore Graphs and Beyond: A Survey of the Degree/Diameter Problem," Electronic J. Combinatorics, 2012.
[Stel20] P. Steller, A Survey of the Degree/Diameter Problem for Undirected Graphs, MS thesis, University of Delaware, 2020.
T2. Cayley Networks: Properties and Applications (Assigned to: Tim Lu)
[Gane17] A. Ganesan, "Cayley Graphs and Symmetric Interconnection Networks," Preprint arXiv:1703.08109, 2017.
[Dema13] M. C. Heydemann, "Cayley Graphs and Interconnection Networks," In Graph Symmetry: Algebraic Methods and Applications, p. 167, 2013.
T3. Cartesian-Product Networks (Assigned to: TBD)
[Yous91] A. Youssef, "Cartesian Product Networks," Proc. Int'l Conf. Parallel Processing, pp. 684-685, 1991.
[Mora11] R. Moraveji, H. Sarbazi-Azad, and A. Y. Zomaya, "Performance Modeling of Cartesian Product Networks," J. Parallel and Distributed Computing, Vol. 71, No. 1, pp. 105-113, 2011.
T4. Connectivity of Networks (Assigned to: TBD)
[Li16] X. Li and Y. Mao, Generalized Connectivity of Graphs, Springer, 2016.
[Fran92] A. Frank, "Augmenting Graphs to Meet Edge-Connectivity Requirements," SIAM J. Discrete Mathematics, Vol. 5, No. 1, pp. 25-53, 1992.
T5. Hamiltonicity of Networks (Assigned to: TBD)
[Kewe11] C. D. Z. Kewen, "A Survey of the Advances of Hamiltonicity on Simple Graphs," Mathematical Theory and Applications, 2011.
[Xu09] J. M. Xu and M. Ma, "Survey on Path and Cycle Embedding in Some Networks," Frontiers of Mathematics in China, Vol. 4, No. 2, pp. 217-252, 2009.
Poster Preparation and Presentation Tips
 Here are some guidelines for preparing your research poster. The idea of the poster is to present your research results and conclusions thus far, get oral feedback during the session from the instructor and your peers, and to provide the instructor with something to comment on before your final report is due (no presentation for winter 2021, so the instructor feedback will be written). Please send a PDF copy of the poster via e-mail by midnight on the poster due date.
Here are some guidelines for preparing your research poster. The idea of the poster is to present your research results and conclusions thus far, get oral feedback during the session from the instructor and your peers, and to provide the instructor with something to comment on before your final report is due (no presentation for winter 2021, so the instructor feedback will be written). Please send a PDF copy of the poster via e-mail by midnight on the poster due date.
Posters prepared for conferences must be colorful and eye-catching, as they are typically competing with dozens of other posters for the attendees' attention. Here are some tips and examples. Such posters are often mounted on a colored cardboard base, even if the pages themselves are standard PowerPoint slides. You can also prepare a "plain" poster (loose sheets, to be taped or pinned to a wall) that conveys your message in a simple and direct way. Eight to 10 pages, each resembling a PowerPoint slide, would be an appropriate goal. You can organize the pages into 2 x 4 (2 columns, 4 rows), 2 x 5, or 3 x 3 array on the wall. The top two of these might contain the project title, your name, course name and number, and a very short (50-word) abstract. The final two can perhaps contain your conclusions and directions for further work (including work that does not appear in the poster, but will be included in your research report). The rest will contain brief description of ideas, with emphasis on diagrams, graphs, tables, and the like, rather than text which is very difficult to absorb for a visitor in a short time span.
Grade Statistics
 All grades listed below are in [0.0, 4.3] (F to A+), unless otherwise noted
All grades listed below are in [0.0, 4.3] (F to A+), unless otherwise noted
HW1 grades: Range = [B–, A], Mean = 3.6, Median = A–
HW2 grades: Range = [B–, A], Mean = 3.5, Median = A–
HW3 grades: Range = [B–, A], Mean = 3.5, Median = A–
HW4 grades: Range = [C+, A], Mean = 3.2, Median = B+
HW5 grades: Range = [B, A], Mean = 3.7, Median = A–
Overall homework grades (percent): Range = [52, 100], Mean = 82, Median = 87
Research paper/poster grades: Range = [B, A], Mean = 3.7, Median = A–
Course letter grades: Range = [B, A+], Mean = 3.6, Median = B+/A–
References

Required text: B. Parhami, Introduction to Parallel Processing: Algorithms and Architectures, Plenum Press, 1999. Make sure that you visit the textbook's web page which contains an errata. Lecture slides are also available there.
Optional recommended book: T. Rauber and G. Runger, Parallel Programming for Multicore and Cluster Systems, 2nd ed., Springer, 2013. Because ECE 254B's focus is on architecture and its interplay with algorithms, this book constitutes helpful supplementary reading.
On-line: N. Matloff, Programming Parallel Machines: GPU, Multicore, Clusters, & More. [Link]
Research resources:
The follolwing journals contain a wealth of information on new developments in parallel processing: IEEE Trans. Parallel and Distributed Systems, IEEE Trans. Computers, J. Parallel & Distributed Computing, Parallel Computing, Parallel Processing Letters, ACM Trans. Parallel Computing. Also, see IEEE Computer and IEEE Concurrency (the latter ceased publication in late 2000) for broad introductory articles.
The following are the main conferences of the field: Int'l Symp. Computer Architecture (ISCA, since 1973), Int'l Conf. Parallel Processing (ICPP, since 1972), Int'l Parallel & Distributed Processing Symp. (IPDPS, formed in 1998 by merging IPPS/SPDP, which were held since 1987/1989), and ACM Symp. Parallel Algorithms and Architectures (SPAA, since 1988).
UCSB library's electronic journals, collections, and other resources
Miscellaneous Information
Motivation: The ultimate efficiency in parallel systems is to achieve a computation speedup factor of p with p processors. Although often this ideal cannot be achieved, some speedup is generally possible by using multiple processors in a concurrent (parallel or distributed) system. The actual speed gain depends on the system's architecture and the algorithm run on it. This course focuses on the interplay of architectural and algorithmic speedup techniques. More specifically, the problem of algorithm design for "general-purpose" parallel systems and its "converse," the incorporation of architectural features to help improve algorithm efficiency and, in the extreme, the design of algorithm-based special-purpose parallel architectures, are dealt with. The foregoing notions will be covered in sufficient detail to allow extensions and applications in a variety of contexts, from network processors, through desktop computers, game boxes, Web server farms, multiterabyte storage systems, and mainframes, to high-end supercomputers.
Catalog entry: 254B. Advanced Computer Architecture: Parallel Processing(4) PARHAMI. Prerequisites: ECE 254A. Lecture, 4 hours. The nature of concurrent computations. Idealized models of parallel systems. Practical realization of concurrency. Interconnection networks. Building-block parallel algorithms. Algorithm design, optimality, and efficiency. Mapping and scheduling of computations. Example multiprocessors and multicomputers.
History: The graduate course ECE 254B was created by Dr. Parhami, shortly after he joined UCSB in 1988. It was first taught in spring 1989 as ECE 594L, Special Topics in Computer Architecture: Parallel and Distributed Computations. A year later, it was converted to ECE 251, a regular graduate course. In 1991, Dr. Parhami led an effort to restructure and update UCSB's graduate course offerings in the area of computer architecture. The result was the creation of the three-course sequence ECE 254A/B/C to replace ECE 250 (Adv. Computer Architecture) and ECE 251. The three new courses were designed to cover high-performance uniprocessing, parallel computing, and distributed computer systems, respectively. In 1999, based on a decade of experience in teaching ECE 254B, Dr. Parhami published the textbook Introduction to Parallel Processing: Algorithms and Architectures (Website).
Offering of ECE 254B in winter 2022 (Link)
Offering of ECE 254B in winter 2021 (Link)
Offering of ECE 254B in winter 2020 (Link)
Offering of ECE 254B in winter 2019 (Link)
Offering of ECE 254B in winter 2018 (Link)
Offering of ECE 254B in winter 2017 (Link)
Offering of ECE 254B in winter 2016 (PDF file)
Offering of ECE 254B in winter 2014 (PDF file)
Offering of ECE 254B in winter 2013 (PDF file
Offering of ECE 254B in fall 2010 (PDF file)
Offering of ECE 254B in fall 2008 (PDF file)
Offerings of ECE 254B from 2000 to 2006 (PDF file)